|
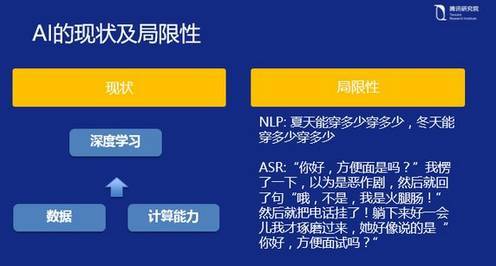
讲了很多深度学习的内容,刚才谈到深度学习的快速发展,它的方法很好,模型也很好,数学算法也在突破,但是现状是什么呢?今天我想谈的话题是大家对 AI 的期待很大,但期待有些过,为什么会这么讲?作为一个从业者,我认为目前 AI 上还是有很多局限的,可能需要提出来,与大家一起探讨。 第一个是深度学习本身所具备的能力,即大家所说的将 AI 与人类相比,存在多大的差距。实际上如今所有的深度学习方法,不论这个方法有多么的新,其学习过程都是要从头开始,需要经历数据重新训练的过程。这一点和人的学习能力相比确实有很大的差距,因为人有很多的智能是与生俱来的,如小孩刚出生,他感知这个世界是三维的并不需要多长时间,并且如果你将一个物体放在电视机后面,他会知道电视机后面有这样一个物体,这些能力是与生俱来的,其与生物的进化是相关的。所以灵长类动物和单细胞生物相比是有与生俱来的能力的,人类的小孩不需要再次经历单细胞演进到灵长类动物这一过程。但在目前的深度学习方法下,不论我们提出了多么优秀的模型,其都需要从最开始的数据开始学。这和人类的学习能力相比,是一个巨大的缺陷。 第二个是计算能力。不论是多么好的深度学习模型或者神经网络出现,本质上还是通过计算能力去解决大数据的问题,更好的计算能力去做更好的拟合。在这个计算力上面,过往的十年是整个硬件发展的十年,是符合摩尔定律的。但是在以后需要训练更多参数的情况下,我们能否有足够的计算力以达到预期效果还有待商榷。 从 2012 年提出来的 AlexNet 网络模型,这个模型在当时的 ImageNet 挑战赛中获得冠军,到剑桥大学提出的 VGGNet,谷歌提出的 GoogleNet,再到 2015 年 MSR 提出的残差神经网络 ResNet,每一次新模型的提出都伴随着模型层级的增加、神经单元复杂度的加强、训练过程的加长,当然得出来的结果也更好。但是这种通过计算力去解决问题的方式是不是还能像以前一样可持续,有待商榷。 刚才所说的都是图像方面的研究,谈及人工智能来解决系统认知问题,那么与人的差距就更大了。人类语言是一个序列问题,这个语言序列问题如果通过神经网络去训练的话,仅通过计算力是不可能解决这个问题的。人在对话当中很容易回溯到长时间语句的某个片段关键词里。但在机器学习中却不一定能做到这样,虽然从最早的 RNN 模型中构建了 LSTM(长短期记忆单元)模式,后来又提出了带注意力的模型。但总体上,这种模型的演进和人类相比是远不如人类的。举个自然语言处理(NLP)的例子,有三个人在对话,两个人在聊湖人跟快船的比分是几比几,然后中间有大段话题转到去哪里吃饭,突然插进来第三个人问太阳呢?机器这时候很难理解「太阳」到底是哪个太阳,聊天者知道这是描述太阳队,因为在「去哪吃饭」这个话题前有湖人和快船的话题。但是机器基本上没办法识别,又如「夏天能穿多少穿多少,冬天能穿多少穿多少」,这两句基本一样,但前面的描述突出少,后面的突出多。这种认知行为到目前为止,深度学习上再先进的方法也没办法处理。 第二个例子是语音识别,我看过一个笑话,语音识别很难处理,「您好,方便面试吗?」我在重复这句话的时候,我都不知道自己在讲方便面——是吗,还是方便——面试吗,这的确是一个非常难的问题。但是人的理念里有很多东西,是可以通过反问,多次获取信息来最终理解。所以说目前人工智能情况,在图像方面,例如人脸识别的精确率有多么高能达到 99% 的识别率,但实际上是在很多的约束条件下才能实现,识别正脸的模型不能识别侧脸,或者是把同一个人的侧脸完全识别成另外一个人。在语音识别里也是如此,目前语音识别是在获取的信息源很干净的情况下才能有很好的效果,比如噪音比较小、没有混响、没有风噪和车噪,在这样的条件下,机器在听语音识别的时候才可能会识别出比较好的效果。但对人来说,这完全不是问题,以及多人的面部识别,语音跟踪,这些对人来说都不是很难。但是对机器而言,即便在我刚刚所说的感知领域——图像识别和语音识别,它跟人基本的能力相比还有很大差距,更别提在认知的任务处理上,比如 NLP 的语意理解。
|