|
因此,考虑到出现频率,我们可以减少一个词汇库中每个词中的平均比特数。在这个例子中,我们从 13.3 减少到 9.16,相当于加速了 31%。Mikolov 等人 [1]把哈夫曼树运用在多层次 softmax,把更少的比特赋给更常出现的词。比如,「the」这个最常见的英语单词,在树中只需要最少比特数的编码,而第二常见的单词将会被指定第二少比特数的编码,以此类推。虽然我们仍然需要用相同数量的词去编码一个数据集,然而有更高频率出现短的编码,所以平均而言,去给每个词编码只需用更少的比特数。 一个类似于哈夫曼编码的编码又被称为信息熵编码,因为每个编码词的长度大约是和我们观察到的每个符号的熵成正比。Shannon [5] 在他的实验中建立了英语的信息率的下界,每个字母大约是 0.6 到 1.3 比特;根据每个词的长度为 4.5,这相当于每个单词为2.7到5.85比特。 将这个和语言建模(我们在上一篇博文中讲到的那样)联系起来:语言模型的评价标准的困惑度应该是 2H,其中H就是信息熵。一个一元的熵是 9.16,因此它有一个非常高的困惑度 2^9.16=572.0。我们可以将这个值更加具体化,观察一个困惑度为572的模型就像从一个信息源中选择单词,而每个单词有572种选择,每种选择概率相等,且互相独立。 这么说吧:Jozefowicz 等人在 2016 年开发的这个最新的语言模型,在 1B Word Benchmark 中,每个词拥有 24.2 的困惑度。这个模型因此需要大约4.60比特来编码一个词,因为 2^4.60=24.2,非常接近于 Shannon 描述的实验下界。我们能否,以及如何使用这个模型去建立一个更好的多层次 softmax 层?这些问题仍留待我们去探索。 微分 Softmax 方法 Chen等人[9]介绍了一个经典 softmax 层的变形—— 微分Softmax(Differentiated Softmax,英文缩写为D-Softmax)。D-Softmax 基于不是所有的单词都需要同样多的参数:许多高频词可以拟合许多参数,而非常低频词则只能拟合很少的参数。 为了做到这一点,他们不用常规 softmax 层的 d×|V| 大小的包含输出词嵌入 的稠密矩阵,而用一个稀疏矩阵。然后他们把 v′w 排列成块,根据他们的频率排列,而每块的词嵌入的维度都是 dk。块的数量和他们的向量大小均为可以优化的超参数。
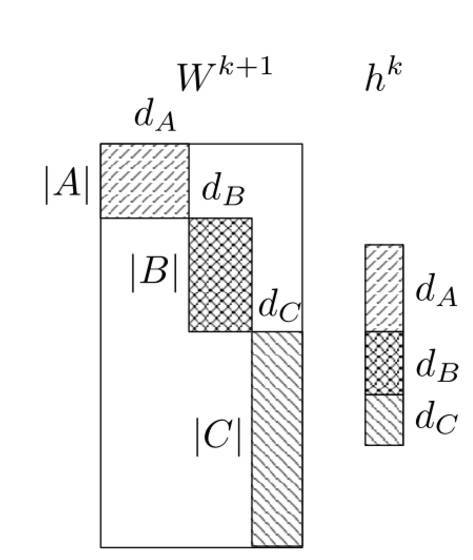
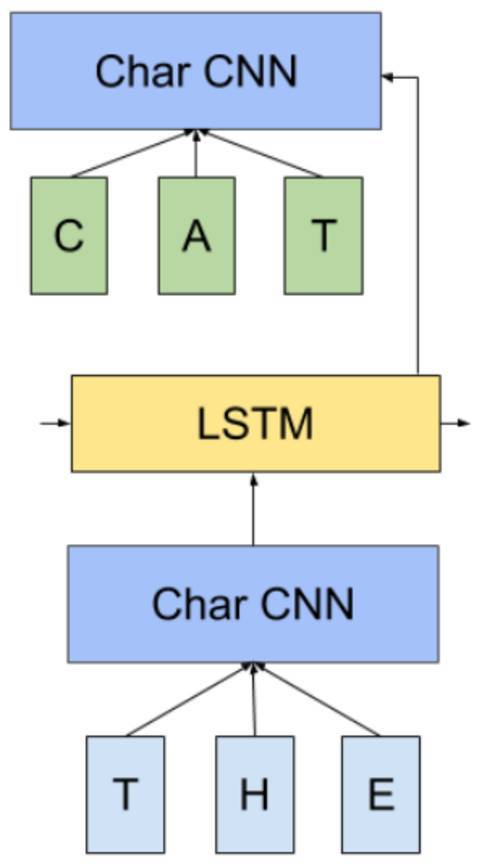
图3:微分 softmax(Chen等人(2015)) 图3中,分区A的词嵌入的维度是 dA(这些是高频词的词嵌入,因为它们被赋予更多的参数),而分区 B 和 C 的词嵌入分别有 dB 和 dC 维度。注意到所有不属于任何分区的区域,也就是图1中的这些没有阴影的区域,都设为 0。 之前的隐藏层 h 都被当成是把每个对应维度的分区的特征串在一起。在图3中的h由大小分别为 dA、dB 和 dB 的分区组成。D-Softmax 不计算矩阵-向量的乘积,而是计算每个分区的乘积和它们在h的分区。 因为许多词只需要相对来说较少的参数,计算 softmax 的复杂度降低了。对比 H-Softmax,这个加速在测试阶段仍然存在。Chen 等人(2015)发现 D-Softmax 是在测试阶段最快的方法,而且是最准确的模型之一。然而,因为它给低频词赋予了更少的参数,D-Softmax 对于低频词的建模效果并不好。 CNN-Softmax 方法 另一个对经典 softmax 层的改进受到了 Kim 等人最近的对于通过一个字母层次(character-level)的 CNN 的输入词嵌入 vw 的研究启发。Jozefowicz 等人(2016)建议对输出词嵌入做相同的事情,即通过一个字母层次的CNN。注意到如果我们像在图4中的在输入和输出有一个 CNN,生成输出词嵌入 v′w 的 CNN 必须和生成输入词嵌入 vw 的 CNN 不一样,就像是输入词嵌入和输出词嵌入必须不一样。
图4: CNN-Softmax(Jozefowicz 等人 ,2016年) 虽然这个仍然需要计算常规 softmax 的标准化,这个方法很大程度上减少了模型参数的数量:我们现在不存储d×|V|的词嵌入矩阵,而仅仅是追踪 CNN 的参数。在测试阶段,输出向量 v′w 可以提前计算,所以模型的表现不会受损。 然而,因为字母都在练习空间中表现,且因为得到的矩阵都倾向于学习一个把字母映射到词的平滑函数,基于字母的模型常常会难以区分拼写相似而意思迥异的词。为了避免这个问题,研究者们加上一个通过每个词学习的连接系数,就能很大程度地减少常规的 softmax 和 CNN-softmax 的表现差异。调整修正项(correction term)的维度,研究者就可以取得模型大小和表现好坏的平衡。 (责任编辑:本港台直播) |