|
为了在数学上比较这两个「图」的相似性,交叉熵是一个好方法。(这里是一个很棒但比较长的解释,如果你对细节感兴趣的话。https://colah.github.io/posts/2015-09-Visual-Information/) 然而,为了利用交叉熵,我们需要将实际结果向量(y')和预测结果向量(y)转换为「概率分布」,「概率分布」意味着: 每个类的概率/分数值在 0-1 之间; 所以类的概率/分数和必须是 1; 实际结果向量(y')如果是 one-hot 向量,满足了上述限制。 为预测结果向量(y), 使用 softmax 将其转换为概率分布:
softmax 函数,这里 i 是表示 0, 1, 2, …, 9 十类 这个过程只需要简单的两步,预测向量(y)中的每个分量是 exp(y_i) 除以所有分量的 exp() 的和。
注意:softmax(y)图形在形状上与 prediction (y) 相似,但是仅仅有较大的最大值和较小的最小值
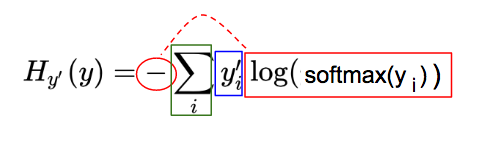
使用 softmax 前后预测(y)曲线 第三步:交叉熵 现在,我们将预测向量分数概率分布(y')和实际向量分数概率分布 (y) 运用交叉熵。 交叉熵公式: 交叉熵作为我们想最小化的成本函数 为了快速理解这个复杂的公式,我们将其分为 3 部分(见下文)。注意,本文中的符号,我们使用 y_i 表示 y 的第 i 个分量。
交叉熵(H)公式可视为三个部分:红,蓝,绿 蓝:实际图像类(y')对应的 one-hot 图,参看 one-hot 向量部分: 红:由预测向量元素(y)经过softmax(y),-og(softmax(y)一系列变化而来: 绿:每一图片类别 i,其中,i = 0, 1, 2, …, 9, 红蓝部分相乘的结果 以下图例会进一步简化理解。 蓝色制图只是真实图片类别(y')one-hot 向量。
每个预测向量元素,y,转换成 -log(softmax(y),就得到红图:
预测类别向量(y)一系列转换后,得到红图 如果你想完全地理解第二个变换 -log(softmax(y)) 与 softmax(y) 为什么成反比,请点击 video or slides(参见文末资源部分). 交叉熵(H),这个绿色的部分是每个类别的蓝色值和红色值的乘积和,然后将它们做如下相加:
交叉熵是每个图像类的蓝色值和红色值的乘积之和。 由于这张蓝色图片对应一个 one-hot 向量,one-hot 向量仅仅有一个元素是 1,它对应一个正确的图片类,atv,交叉熵的其它所有元素乘积为 0,交叉熵简化为:
将所有部分放到一起 有了三个转换后,现在,我们就可以将用于线性回归的技术用于逻辑回归。下面的代码片段展示的是本系列文章第三部分线性回归代码和代码适用逻辑回归所需要的变化之间的对比。 逻辑回归的目标是最小化交叉熵(H),这意味着我们只需要最小化 -log(softmax(y_i)项;因为该项与 softmax(y_i)成反比,所以我们实际上是最大化该项。 使用反向传播去最小化交叉熵 (H ) 将改变逻辑回归的权重 W 和偏置 b。因此,每张图片的像素值将会给出对应图片类最高分数/概率!(最高分数/概率对应于正确的图片类)
|