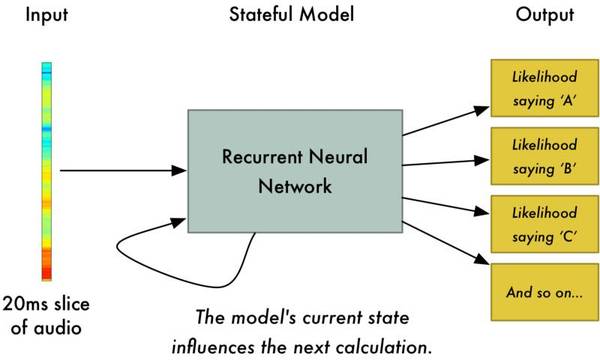
|
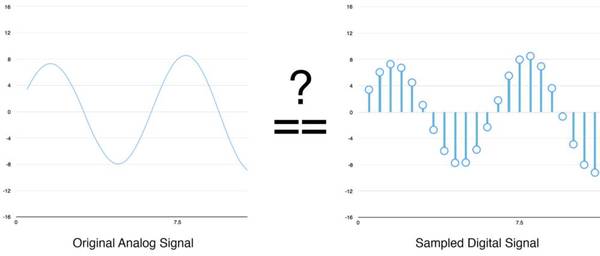
你可能认为采样只是原始声波的粗略近似,因为它只是偶然的读数。我们的读数之间有间隔,所以我们必定会丢失一些数据,是这样吗?
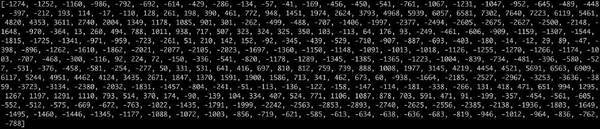
(左)原始模拟信号;(右)采样的数字信号 但是,由于Nyquist定理,我们其实可以使用数字信号从有间隔的样本完全重建原始的声波——只要我们采样的频率至少比我们想要记录的最高频率高两倍。 我提到这点是因为几乎每个人都会在这一点上弄错,会认为使用更高的采样率能得到更好的音频质量。其实不是的。 预处理采样的音频数据 我们现在已经有一组数字阵列,每个数字代表声波间隔1/16000秒的振幅。 我们可以把这些数字馈送入神经网络,但是试图直接处理这些样本来识别语音模式是很困难的。相反,通过对音频数据进行一些预处理能让问题更容易。 让我们先把采样的音频以20毫秒长的块来分组。以下是第一个20毫秒的音频(即前320个样本):
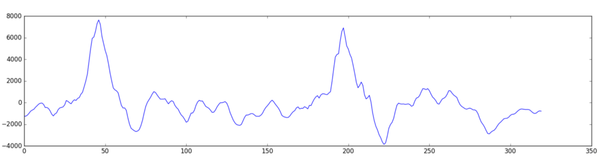
将这些数字绘成图,得出20毫秒时间段的原始声波的粗略近似:
这样一个记录的长度只有1/50秒,但这样一个短录音已经包含复杂的不同频率的声音,有低音,有中音,甚至还有一些高音。但总的来说,这些不同的频率混合在一起,组合成复杂的人类语音。 为了让这些数据更容易为神经网络处理,我们把这些复杂的声波分解为一个个组成部分。我们将它分解为低音部分,更低音部分,等等,然后将每个频带(从低到高)的能量相加,为该音频片段创建一个有排序的识别码。 我们使用傅立叶变换运算来实现这点,它能将复杂的声波分解为简单的声波。当我们有了这些单独的声波,可以将每一个部分所包含的能量加在一起。最终得到的结果是从低音到高音的每个频率范围的重要程度得分。下图的每个数字表示这段20毫秒的音频中每个50Hz的频带的能量:
把这些数字绘制成图表:
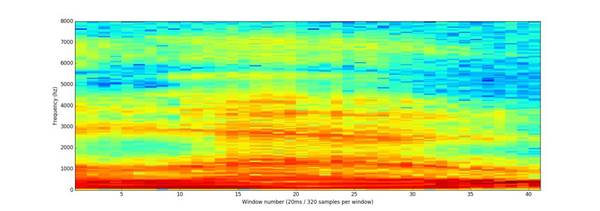
可以看到,这段20毫秒的声音片段中有很多低频能量,而更高的频率没有太多能量。这是典型的男性声音。 如果我们对每个20毫秒的音频片段重复这个过程,最终能得到一个频谱图(每一列从左到右是一个20ms的片段):
“Hello”音频的完整频谱图 这个谱图很酷,因为你能够实际看到音频数据中的音符以及其他音高模式。神经网络在这种形式的数据中能够比从原始声波数据更容易找到模式。因此,这种数据呈现是我们实际馈送给神经网络的输入。 从短音频中识别字符 现在我们将格式易于处理的音频数据输入到深度神经网络中,这些输入是20毫秒的音频片段。对于每个片段,神经网络将试图找出对应于当前声音的字母。
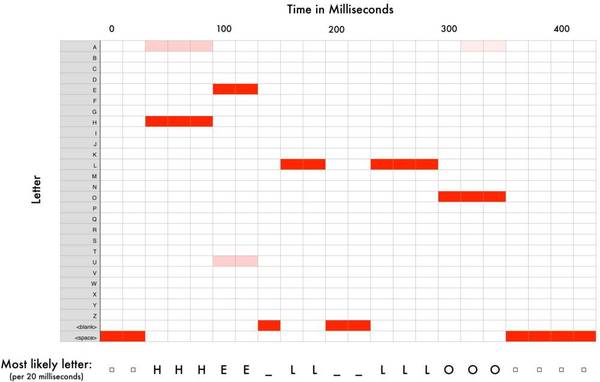
我们使用一个循环神经网络来预测每个字母对下一个字母的影响可能性。例如,如果我们已经识别到“HEL”,atv直播,那么很可能接下来的字母是“LO”,以完成“Hello”,而不太可能是“XYZ”之类的字母。因此,具有先前预测的记忆有助于神经网络进行更准确的预测。 在我们通过神经网络(每次一个片段)处理完整个音频后,我们将最终得到每个音频片段和最可能的字母的映射。下图是“Hello”的映射的样子:
神经网络预测我说的一个可能是“HHHEE_LL_LLLOOO”。但它也认为有可能我说“HHHUU_LL_LLLOOO”甚至“AAAUU_LL_LLLOOO”。 我们有一些步骤来使输出更干净。首先,我们需要用单个字符替换重复的字符: HHHEE_LL_LLLOOO变为HE_L_LO HHHUU_LL_LLLOOO变为HU_L_LO AAAUU_LL_LLLOOO变为AU_L_LO 然后,删除所有空格: HE_L_LO变为HELLO HU_L_LO变为HULLO AU_L_LO变为AULLO (责任编辑:本港台直播) |