|
在围棋和德州扑克后,RTS 游戏《星际争霸》已经成为人工智能研究者们征服的下一个目标。近日,来自阿里巴巴和伦敦大学学院(UCL)的研究者们发表了一项新研究,他们宣称人工智能控制的多个游戏单位在无监督学习的情况下已经可以发展出类似于人类玩家的战术。这种协同多个人工智能体新方法或许可以为研究者们带来启示, 过去十年里,人工智能技术有了突飞猛进的发展。在有监督学习的情况下,机器已经可以展现达到甚至超越人类认知水平的和能力。而在指定奖励目标后,单体人工智能(即智能体,agent)在 、和等项目上也打败了人类最强选手。 然而,人类智慧很大一部分在于社会和集体智慧,j2直播,这也是实现通用人工智能的基础。人工智能的下一大挑战在于让不同智能体实现合作与竞争。对于研究者而言,经典即时战略游戏(RTS)《星际争霸》是进行此类实验的绝佳实验环境。在游戏中,每个玩家都需要控制不同的兵种,在不同的地形条件下与对手展开斗争。《星际争霸》系列游戏因为变化的多样性,对人工智能而言比围棋更加复杂,。同时,这种大型多智能体系统的协同学习面临着计算性能的限制——参数空间会随着涉及智能体数量的增多而呈指数性增长,这意味着任何联合学习的方式都是无效的。 在本研究中,来自阿里巴巴和 UCL 的研究者们把多智能体星际争霸战斗任务设定为零和随机游戏。不同智能体通过新提出的双向协调网络(BiCNet)来相互交流,而学习是通过评估-决策方式来完成的。此外,研究者们还提出了共享参数与动态分组的概念,以解决扩展性的问题。 论文:Multiagent Bidirectionally-Coordinated Nets for Learning to Play StarCraft Combat Games
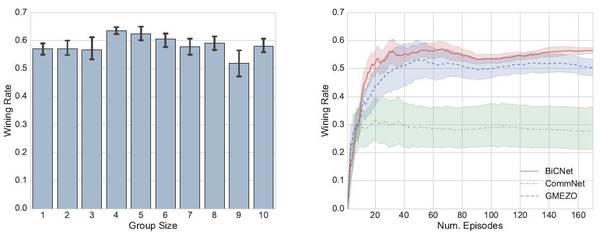
摘要 现实世界的人工智能(AI)应用通常需要多个智能体协同工作。人工智能体之间有效的沟通和协调是迈向通用人工智能不可或缺的一步。在本论文中,我们以 RTS 游戏《星际争霸》为测试场景,设定任务为多个智能体互相协作试图击败敌人。为了保证沟通方式有效且可扩展,我们引入了多智能体双向协调网络(BiCNet),它具有向量化扩展评价器(actor-critic)形式。我们验证了 BiCNet 可以协调不同兵种,在不同的场景和两方智能体数量任意的情况下正常工作。我们的分析证明,在没有手动标记数据进行监督学习的情况下,BiCNet 可以学会多种有经验的人类玩家展示出的协调策略。而且,BiCNet 能够轻松适应异构智能体任务。在实验中,我们在不同的场景下用我们的新方法与不同的基准进行了对比;BiCNet 展现出了最先进的性能,它具有在现实世界大规模应用的潜在价值。
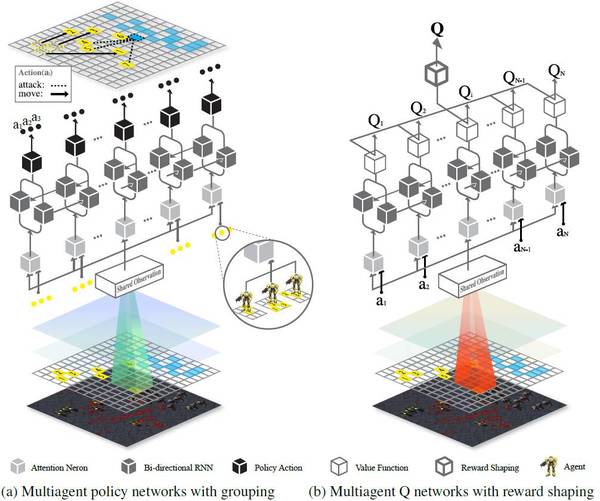
图 1:双向协调网络(BiCNet)示意
图 2:三个机枪兵(人工智能)对阵一个提速狗(小狗的升级,加移动速度和攻击速度)。如图(a)和(b)显示,j2直播,在训练初期三个单位会发生碰撞,而在充分训练后(图 c、d),各智能体学会了协调一致。
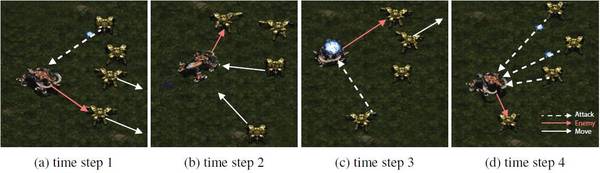
图 3:三个机枪兵(人工智能)对阵一个狂热者(敌人)时学会了 Hit and Run 策略。
图 4:四个龙骑(人工智能)围杀一个雷兽(敌人),被攻击的龙骑学会了躲避。
图 5:三个机枪兵(人工智能)围杀一个小狗(敌人)。 在三个机枪兵对阵一个小狗的任务中(图 5),研究人员调整敌人的数量和小狗的血量与攻击力进行了多次测试。实验发现,BiCNet 只会在小狗血量高于 210,攻击力为 4 的情况下使用围杀策略,而小狗的默认血量为 35,攻击力为 5。
表 1:人工智能在不同血量和攻击力敌人情况下的胜率。训练步数 100k/200k/300k。
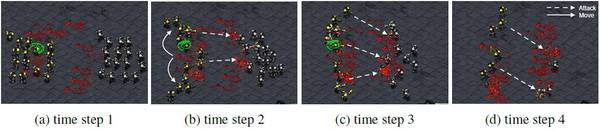
图 6:人工智能在十五个机枪兵对战的情况下学会了「集火」策略。
图 7:控制多兵种的人工智能协同完成任务:两架运输机、两个坦克对阵一个雷兽。
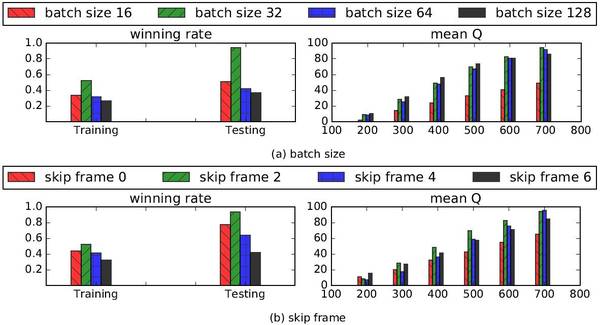
图 8:batch_size 和 skip_frames 在两个机枪兵对一个提速狗的任务中对胜率产生的影响。
|