|
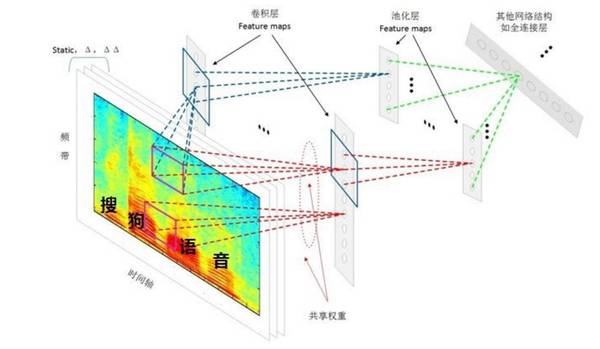
DFCNN 的结构如图所 示,DFCNN 直接将一句语音转化成一张图像作为输入,即先对每帧语音进行傅里叶变换,再将时间和频率作为图像的两个维度,然后通过非常多的卷积层和池化(pooling)层的组合,对整句语音进行建模,输出单元直接与最终的识别结果(比如音节或者汉字)相对应。 搜狗语音识别 纵观整个互联网行业,可以说搜狗作为一家技术型公司,在人工智能领域一直依靠实践来获取更多的经验,从而提升产品使用体验。 在前几天的锤子手机新品发布会上罗永浩现场演示了科大讯飞的语音输入之后,一些媒体也对科大讯飞和搜狗的输入法的语音输入功能进行了对比,发现两者在语音识别上都有很不错的表现。比如《齐鲁晚报》的对比结果: 值得一提的是,得益于创新技术,搜狗还拥有强大的离线语音识别引擎,在没有网络支持的情况下依旧可以做到中文语音识别,以日常语速说话,语音识别仍然能够保持较高的准确率。这一点科大讯飞表现也较为优秀,两者可谓旗鼓相当。 整体体验下来,搜狗在普通话和英文的语音输入方面表现,与讯飞相比可以说毫不逊色,精准地识别能力基本可以保证使用者无需进行太多修改。此前在搜狗的知音引擎发布会上,搜狗语音交互技术项目负责人王砚峰称「搜狗知音引擎具备包括端到端的语音识别、强大的智能纠错能力、知识整合使用能力以及多轮对话和复杂语义理解能力」,这些都有效保证了搜狗语音输入在识别速度、精准度、自动纠错、结合上下文语意理解纠错方面收获不错的表现。 八月份,搜狗发布了语音交互引擎——知音,其不仅带来了语音识别准确率和速度的大幅提升,还可以与用户更加自然的交互,支持多轮对话,处理更复杂的用户交互逻辑,等等。知音平台体现出搜狗在人工智能技术领域的长期积累,同时也能从中看出他们的技术基因和产品思维的良好结合。
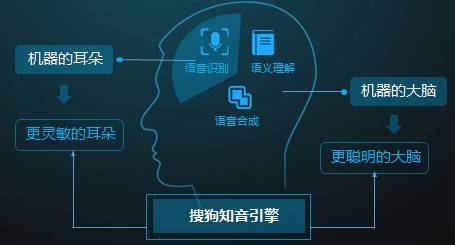
搜狗知音引擎 搜狗把语音识别、语义理解、和知识图谱等技术梳理成「知音交互引擎」,这主要是强调两件事情,j2直播,一是从语音的角度上让机器听的更加准确,这主要是识别率的提升;另一方面是让机器更自然的听懂,这包括在语义和知识图谱方面的发展,其中包括自然语言理解、多轮对话等技术。
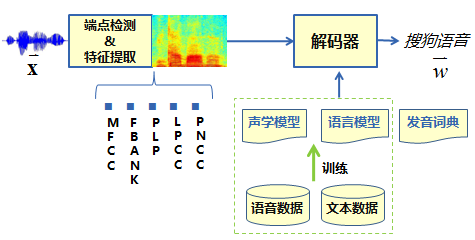
语音识别系统流程:语音信号经过前端信号处理、端点检测等处理后,逐帧提取语音特征,传统的特征类型包括 MFCC、PLP、FBANK 等特征,提取好的特征送至解码器,在声学模型、语言模型以及发音词典的共同指导下,找到最为匹配的词序列作为识别结果输出。
CNN 语音识别系统建模流程 据搜狗上个月的一篇微信公众号文章写道: 在语音及图像识别、自然语言理解等方面,基于多年在深度学习方面的研究,以及搜狗输入法积累的海量数据优势,搜狗语音识别准确率已超 97%,位居第一。 不过遗憾的是,搜狗还尚未公布实现这一结果的相关参数的技术信息,所以我们还不清楚这样的结果是否是在一定的限定条件下实现的。 就像TechCrunch 统计的美国有 26 家公司开发语音识别技术一样,中国同样有一批专注自然语言处理技术的公司,其中云知声、思必驰等创业公司都在业内受到了极大的关注。
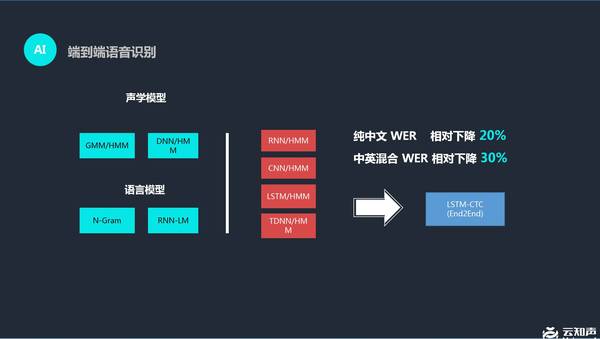
上图展示了云知声端到端的语音识别技术。材料显示,云知声语音识别纯中文的 WER 相对下降了 20%,中英混合的 WER 相对下降了 30%。 在今年 6 月机器之心对云知声 CEO 黄伟(参见:)的专访中,黄伟就说过 2012 年年底,他们的深度学习系统将当时的识别准确率从 85% 提升到了 91% 。后来随着云知声不断增加训练数据,如今识别准确率已经能达到 97% ,属于业内一流水平,在噪音和口音等情况下性能也比以前更好。 (责任编辑:本港台直播) |