|
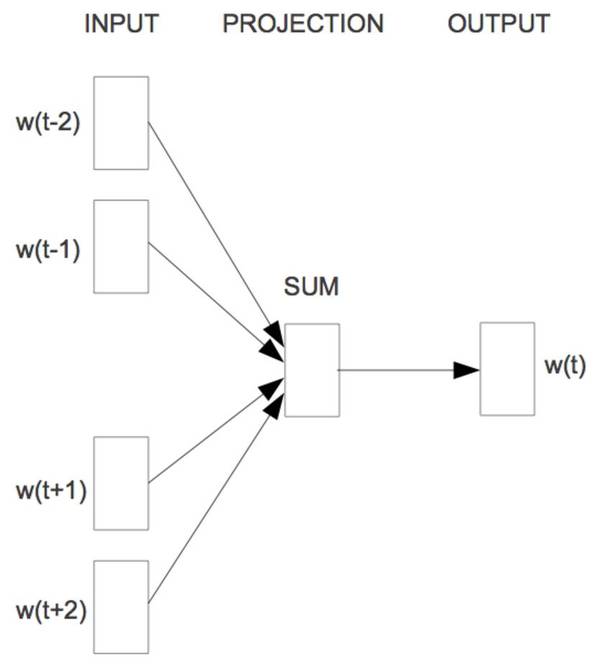
让我们现在介绍当今毫无疑问最为流行的词嵌入模型 word2vec,它源于 Mikolov 等人在 2013 年中两篇论文,且催生了上千篇词嵌入的论文。正因为词嵌入模型是自然语言处理中深度学习的一个关键的模块,word2vec 通常也被归于深度学习。然而严格上来说,word2vec 并不属于深度学习,因为它的架构并非多层,也不像是 C&W 模型一般运用非线性模型。 在他们的第一篇文章 [2] 中,Mikolov 等人提出了更低计算成本的学习词嵌入的两个架构。他们的第二篇论文 [3] 通过加入更多的提升了训练速度和准确度的策略来提升了模型。 这些架构提供了对比于 C&W 模型和 Bengio 模型具有如下两大优点: 他们去掉了昂贵的中间层。 他们运用语言模型来更多地考虑上下文。 我们等等会讲到,他们的模型之所以成功不仅是因为这些改变,而更是因为某些特定的训练策略。 接下来,我们会来看这两个架构: 连续的词袋(CBOW) 言模型只能通过观察之前出现的词来进行预测,且对于此类模型的评价只在于它在一个数据集中预测下一个词的能力,训练一个可以准确预测词嵌入的模型则不受此限。Mikolov 等人运用目标词前面和后面的 n 个词来同时预测这个词,见图 4。他们称这个模型为连续的词袋(continuous bag-of-words,或者 CBOW),因为它用连续空间来表示词,而且这些词的先后顺序并不重要。
图 4:连续的词袋(Mikolov 等人,2013 年) CBOW 的目标函数和语言模型仅有着细小差异:
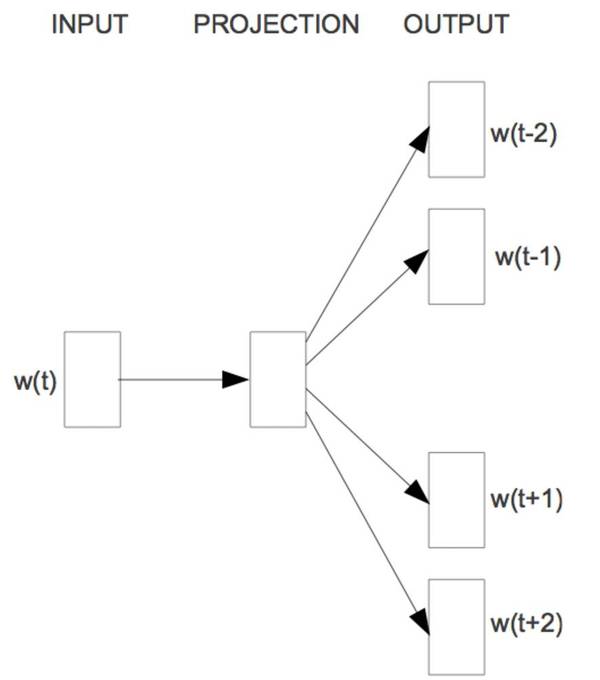
这个模型并没有传入 n 个之前的词,而是在每个时刻 t 接收目标词的前后 n 个词的窗口 w_t。 Skip-gram CBOW 可以看作一个具有先知的语言模型,而 skip-gram 模型则完全改变将语言模型的目标:它不像 CBOW 一样从周围的词预测中间的词;恰恰相反,它用中心语去预测周围的词,如图 5 所示。
图 5:Skip-gram(Mikolov 等人,2013) skip-gram 模型的目标因此用目标词前后的各 n 个词的对数──概率之和计算如下的目标:
为了更直观地解释 skip-gram 模型是怎样来计算 p(w_{t+j}|w_{t}) 的,让我们先来回顾 softmax 的定义:
我们不计算目标词 w_t 基于前面出现的词的概率,而是计算周围词 w_{t+j} 对于 w_t 的概率。于是,我们可以简单地替换掉这些变量:
因为 skip-gram 架构并不包括能够产出中间状态向量 h 的中间层,h 自然地成为对于输入词 w_t 的词嵌入 v_{w_t}。这也是我们为什么想给输入向量 v_w 和输出向量 v′_w 以用不同的表示,因为我们想要将词嵌入和自己相乘。用 v_{w_t} 替换 h,我们得到:
注意 Mikolov 论文中的代号和我们的有细微差别,他们标注词语为 w_I,而周围的词为 w_O。如果我们用 w_I 替换 w_t,用 w_O 替换 w_{t+j},然后根据乘法交换律交换内积的向量位置,我们能够得到和它们论文中一样的公式表示:
下一篇博文,我们将要讨论近似昂贵的 softmax 函数的不同方式,以及令 skip-gram 成功关键的训练决策。我们也会介绍 GloVe[5],一个基于矩阵乘法分解的词嵌入模型,并讨论词嵌入和分布式语义的关系。 References Bengio, Y., Ducharme, R., Vincent, P., & Janvin, C. (2003). A Neural Probabilistic Language Model. The Journal of Machine Learning Research, 3, 1137–1155. (责任编辑:本港台直播) |