|
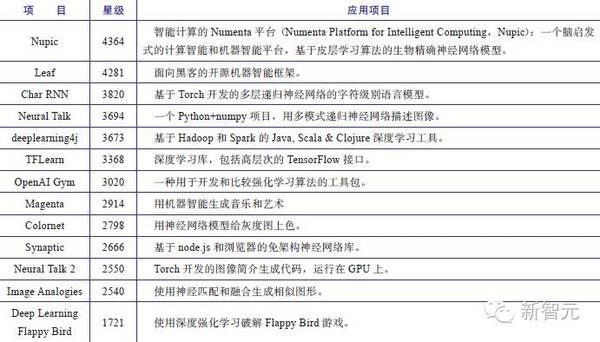
1.模型初步。2006年前后,深度模型初见端倪,这个阶段主要的挑战是如何有效训练更大更深层次的神经网络。2006年,Geoffery Hinton 提出了深度信念网络(DBN),一种深层网络模型。使用一种贪心无监督训练方法来解决问题并取得良好结果。DBN(Deep Belief Networks)的训练方法降低了学习隐藏层参数的难度。并且该算法的训练时间和网络的大小和深度近乎线性关系。这被认为是深度学习的开端,Hinton 也被称为“深度学习之父”。 2.大规模尝试。2011年底,大公司逐步开始进行大规模深度学习的设计和部署。“Google大脑”项目启动,由时任斯坦福大学教授的吴恩达和Google 首席架构师Jeff Dean主导,专注于发展最先进的神经网络。初期重点是使用大数据集以及海量计算,尽可能拓展计算机的感知和语言理解能力。该项目最终采用了16000个 GPU 搭建并行计算平台,以Youtube视频中的猫脸作为数据对网络进行训练和识别,引起业界轰动,此后在语音识别和图像识别等领域均有所斩获。 3.遍地开花。近年来深度学习获得了非常广泛的关注,其进展的一个直观的体现就是ImageNet竞赛。2012年,Hinton 带领的研究团队赢得ILSVRC-2012 ImageNet,计算机视觉的识别率一跃升至80%,标志了人工特征工程正逐步被深度模型所取代。 另外,强化学习技术的发展也取得了卓越的进展。2016年Google子公司DeepMind研发的基于深度强化学习网络的AlphaGo,与人类顶尖棋手李世石进行了一场“世纪对决”,最终赢得比赛,这被认为是深度学习具有里程碑意义的事件。 报告还具体介绍了各家公司,比如Facebook、谷歌、百度、科大讯飞的深度学习技术,对人工智能行业中前沿企业的深度学习技术应用情况进行纵深介绍。报告综合分析认为,深度学习主要在三个领域掀起了革新,分别是:图像识别、语音识别和自然语言处理。 近年来,人工智能技术和行业发展中,开源成为最新并且最强大的趋势之一。经过分析,新智元《2016中国人工智能产业发展报告》认为,深度学习目前表现出来的趋势,不光是技术,还有商业模式的转变。过去几个月,所有巨头都将自己的深度学习IP开源。核心目的是为了吸引用户、扩大市场,吸引人才、加速创新。开源会使技术发展更快,但主宰市场的仍将是巨头。 除了对著名的TensorFlow、Torchnet、Paddle和Caffee等开源平台进行详尽介绍之外,报告还收集汇总了Github上 星级超过1500的深度学习大型开源项目:
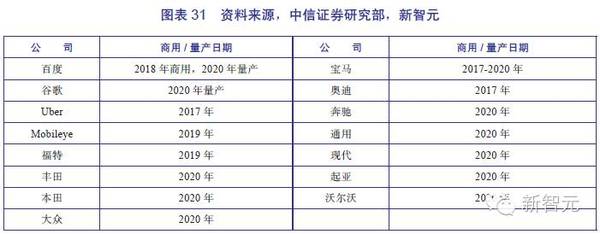
报告综合分析认为,深度学习当下的发展依然存在3大缺陷,需要在接下来的发展中逐渐克服。 深度学习四大缺陷: (1)缺乏理论支持。深度学习方法常常被视为黑盒,大多数的结论确认都由经验而非理论来确定。不管是为了构建更好的深度学习系统,还是为了提供更好的解释,深度学习都还需要更完善的理论支撑。 (2)缺乏推理能力。深度学习技术缺乏表达因果关系的手段,缺乏进行逻辑推理的方法。目前研究者虽然在尝试一些破解此难题的技术,但是效果并不明显。 (3)缺乏短时记忆能力。包括递归神经网络在内的深度学习系统,都不能很好地存储多个时间序列上的记忆。这使得研究人员提出在神经网络中增加独立的记忆模块,如LSTM,记忆网络(Memory Networks),神经图灵机(Neural Turing Machines),和Stack增强RNN(stack-Augmented RNN)。虽然这些方法思路很直观,也取得了一定的成果,但在未来仍需要更多的尝试和新的思路。 (4)缺乏执行无监督学习的能力。虽然无监督学习可以帮助特定的深度网络进行“预训练”,但最终绝大部分能够应用于实践的深度学习方法都采用了纯粹的有监督学习。 3.最热门应用:自动驾驶或在2020年前后普及 人工智能最直观的变革力量体现在应用上。新智元《2016中国人工智能产业发展报告》认为,本年度人工智能最热门的应用当属自动驾驶。
|