|
【倒计时 5 天,点击“阅读原文”抢票!!】? 业界领袖回溯60年AI历史,全球对话人工智能未来挑战,权威发布2016世界人工智能名人堂及中国人工智能产业发展报告;? 国际大咖“视频”远程参会, Bengio 和李飞飞联袂寄语中国人工智能;? 探秘讯飞超脑及华为诺亚方舟实验室,最强CTO与7大研究院院长交锋;? 滴滴CTO与百度首席架构师坐镇智能驾驶论坛,新智元三大圆桌阵容史无前例;? 中国“大狗”与"X-Dog"震撼亮相,龙泉寺机器僧“贤二”卖萌。 最近KDnuggets针对数据科学家最常使用的算法作了一个调查,有一些意外的发现,包括最学术向的算法和最产业向的算法。 下面是调查结果,总调查人数是 844 人。
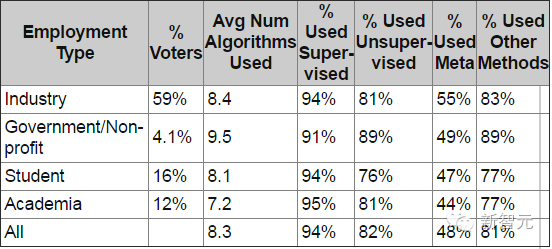
表1:数据科学家最常用的Top 10算法&方法。所有算法和方法的列表在文末。 说明:这个投票的本意是找出数据科学家最常用的工具,但“工具”这个词含义不明确,所以为了简便我最初把这个表成为top 10“算法”。当然,正如有读者指出的,“统计学”或“可视化”以及其他几个都不是算法,更好的描述应该是“方法”。所以我把这个表更名为Top 10算法和方法。 投票者平均使用的算法/方法数是8.1中,比2011年的类似调查增加了很多。 在2011年的调查“数据科学/数据挖掘的常用算法”中,我们提到最常用的方法是回归、聚类、决策树/决策规则,以及可视化。两次调查中投票数增加最多的是: 提升方法,2016年票数占32.8%,2011年占23.5%,票数增加40% 文本挖掘,从2011年的27.7%到2016年的35.9%,票数增加30% 可视化,从2011年的38.3%到2016年的48.7%,票数增加27% 时间序列/序列分析,从2011年的29.6%到2016年的37.0%,票数增25% 异常/偏差检测,从2011年的16.4%到2016年的19.5%,票数增加 19% 集成方法,从2011年的28.3%到2016年的33.6%,票数增加19% SVM,从2011年的28.6%到2016年的33.6%,票数增加18% 回归,从2011年的57.9%到2016年的67.1%,票数增加16% 2016年新增的回答有: K-NN,占比46% PCA,占比43% 随机森林,占比38% 优化,占比24% 神经网络 –深度学习,占比19% 奇异值分解,开奖,占比16% 投票数减少最多的有: 关联规则,从2011年的28.6%到2016年的15.3%,减少了47% 增量建模,从4.8%到3.1%,减少了36% (这个让人吃惊) 因素分析,从18.6%到14.2%,减少了24% 生存分析,j2直播,从9.3%到7.9%,减少了15% 下面的表格表示不同算法类型的应用:监督、无监督、元,及其他,以及投票者职业类型的占比。在职业类型中,我们排除了“未回答”(4.5%)和“其他”(3%)。
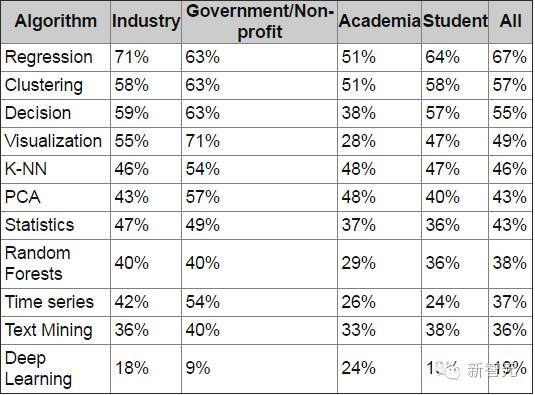
我们发现,几乎所有人都使用监督式学习算法。 政府和产业数据科学家比学生或学术研究人员使用更多不同类型的算法。 产业数据科学家更喜欢元算法。 接下来,我们分析了不同职业人士最常用的10中算法+深度学习: 为了让结果更清晰,我们计算了职业类型和平均算法使用的偏差,即偏差(ALG,类型)=使用(ALG,类型)/使用(ALG,所有)。
图2:按职业类型分的算法使用偏差 我们发现,产业数据科学家更喜欢用回归、可视化、统计、随机森林和时间序列。政府/非营利机构用得更多的是可视化、PCA和时间序列。学术研究者更常用的是PCA和深度学习。学生普遍上使用的算法较少,常用的是文本挖掘和深度学习。 接下来我们分析了能代表 KDnuggets 整体用户的具体地区参与人数: 投票参与者的地区分布: 美国/加拿大,40% 欧洲,32% 亚洲,18% 拉丁美洲,5.0% 非洲/中东,3.4% 澳大利亚/新西兰,2.2% 在2011年的投票中,我们把产业/政府和学术研究者/学生分别合并成一个组,并用以下公式计算产业/政府的算法“亲和度”: N(Alg,Ind_Gov) / N(Alg,Aca_Stu) ------------------------------- - 1 N(Ind_Gov) / N(Aca_Stu) (责任编辑:本港台直播) |