|
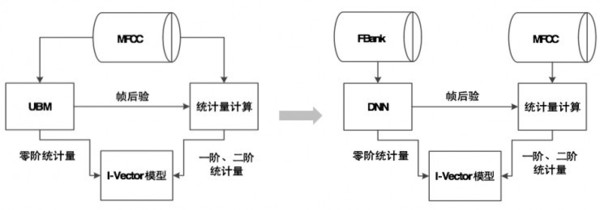
信道特征对说话人识别的准确性干扰很大,如果前期学习建模过程中,能把信道特征统一建模后期在识别的时候,可以实现信道补偿,大大提升说话人识别的鲁棒性。 说话人识别的关键技术——模型训练DNN 我们还可以进一步介入深度神经网络的方式来提取统计量。
用深度神经网络替代一些统一背景模型,可以把音素相关信息通过语音识别的深度神经网络结合起来,采集到更多的说话人特征信息。 音频对比技术 特征提取 音频对比技术也是引用很早很广泛的音频检索技术。
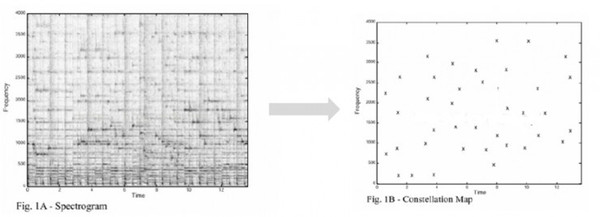
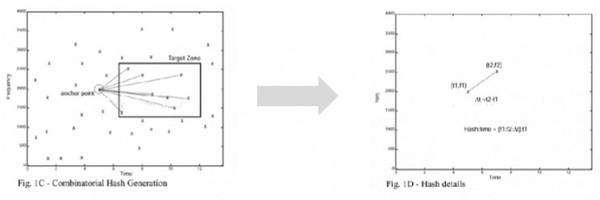
音频对比主要是从音频信号中提取特征,通过特征进行比对来检索。图中提取的过程就是通过频谱最大值点来建模。 特征构建 在完成最大值点完成建模后,我们需要进行特征的构建。
特征构建是通过最大值点之间的距离来建模,例如两个最大值点的距离、位置信息作为一个固定的特征来完成音频特征信息的构建。 检索
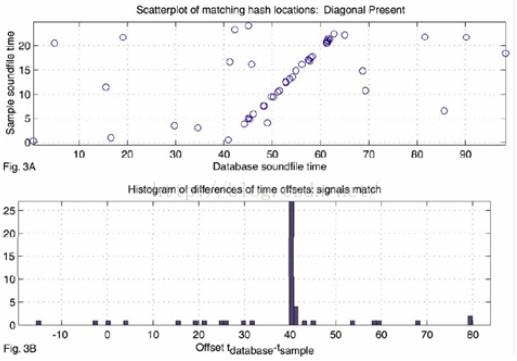
有了上述音频特征之后,就可以对两个不同音频进行检索,最大相似度的地方就是相似点。这种技术最适用于录音片段的检索。 其它技术 1.语音欲处理技术:包括音频编解码、噪声消除(软件处理,硬件解决方案)、语音信号增强。 2.语义识别:对语音识别后的文本结果进行分析,结合上下文,来判断真是意图。 4.流媒体技术:在实时音频数据处理中,需要用到数据切分、数据缓存。 5.云平台技术:云服务架构设计、、服务模块化整合、负载均衡等。 6.大数据技术:海量数据存储、训练样本自动提取、模型训练等。 三、应用场景案例 音频审核数据来源可以分为实时数据和存量数据。存量数据主要是现有的语音资源,实时数据则包括正在直播的广播、电视节目等。 存量音频数据审核 场景:电信运营商诈骗电话检测 这是针对存量数据的解决方案,它有大量的通话录音,而且因为设备供应商的不同,会造成音频格式、音质不统一;另外,电话录音还存在噪声干扰、方言口音问题。 针对这类数据的检测,我们可以提供一套完整的解决方案。
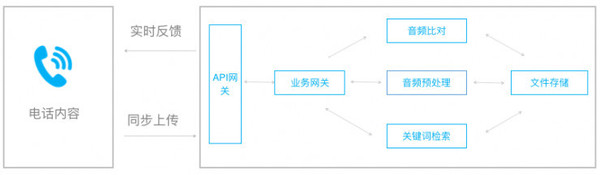
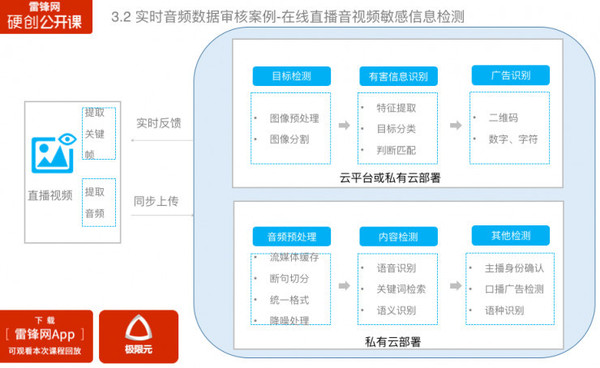
首先把通话录音通过API接口上传到关键词检索服务器上,关键词检索服务器的API网关对它的请求进行分类处理之后,移交给后续的业务网关来分发处理。首先要进行音频预处理,音频格式转码、语音降噪等,然后把处理后的文件存储;接下来,把结果反馈给业务网关,由音频比对对已知录音片段进行检测,如果有匹配这些录音片段就反馈结果——存在诈骗信息。 如果经过音频比对没有发现诈骗信息,我们会调用关键词检索服务。 实时音频数据审核 场景:在线直播平台敏感信息检测 它的数据是实时生成的,需要用到流媒体技术,包含图像、音频两大数据源,所用到的检测技术也不一样。音频检测还分为语种、说话人确认、内容识别。累积了大量的检测数据之后,对后期的模型优化升级也提出了更高的要求。 首先会对直播中的音视频资源提取,分别交由图像处理模块和语音处理模块,针对图像数据我们要提取关键帧,针对语音数据,我们会把视频数据中的音频资源提取出来。
图像数据的处理,拿到图像数据关键帧后会定时发送到处理平台上( 雷锋网注:可以在云端或者私有云部署)。 在图像识别部分要对图像预处理、图像分割,拿到有效的区域来检测,在有害信息识别检测阶段,我么会完成特征提取、目标分类、判断匹配,找出里面涉黄、涉暴的信息。如果用户有进一步的需求,例如广告识别的要求,我们可以根据二维码、数字、字符检测技术来进行广告的识别。 音频的数据提取之后,上传到到服务器端。音频实时处理有个局限是会占用大量的带宽,所以通常采用私有云的部署方式。 (责任编辑:本港台直播) |