|
网络直播行业经历了过去两年的井喷式爆发后,到现在依旧保持着持续火热的态势。但这一市场火爆的背后也一直暴露了一些问题,低俗内容屡见不鲜。显然,要解决这一问题就必须要有比人工鉴黄效率更高的手段,用人工智能技术来鉴黄就是现在直播平台通用的手段。 虽然不少企业都把目光聚焦在视频鉴黄上,但音频审核也是人工智能鉴黄技术的一部分,二者缺一不可。那在大家熟悉的视频鉴黄之外,音频检测究竟能解决哪些问题?这一技术是如何进行鉴黄的呢? 嘉宾介绍
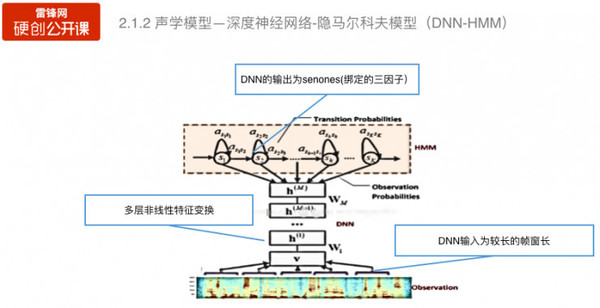
马骥:极限元智能科技联合创始人,曾先后就职于中科院软件研究所、华为技术有限公司,获得多项关于语音及音频领域的专利,资深软件开发工程师和网络安全解决方案专家,擅长从用户角度分析需求,提供有效的技术解决方案,具有丰富的商业交流和项目管理经验。 以下内容整理自本期公开课,雷锋网做了不改变原意的编辑: 一、音视频审核的需求现状 音视频审核主要针对互联网传播的信息进行审核,审核的内容有有害信息(涉黄、涉暴)、敏感信息。 以直播平台为例,2016年,是互联网直播平台爆发的一年,除了各式各样的直播形式。与此同时,也出现了大量的在线实时信息,这其中是有害信息,涉黄是最为严重的一个现象。今年,相关部门已经针对这些乱象加大了打击力度,因此基于互联网直播平台的有害信息检测成为重中之重。 以图像识别技术为基础如何进行鉴黄?在直播的时候,每个直播间会间隔一秒或几秒采集一个关键帧,关键帧会发送到图像识别引擎,引擎根据图像的颜色、纹理等等特征来对敏感图像进行过滤,这一过程会检测肢体轮廓等关键特征信息,然后对检测图像特征与特征库模型里面的特征相似度进行匹配,给予待测图像色情、正常、性感等不同维度的权重值,以权重值最高的作为判定结果输出。 基于图像识别得视频涉黄检测准确率可以达到99%以上,可以为视频直播平台节省70%以上的工作量。 还有一些是语音为主的直播节目,比如谈话聊天、脱口秀、在线广播等。视频检测所使用到的图像技术就很难在这些应用场景发挥作用,所以音频检测需要有针对性的技术手段。 除了刚刚提到的几个音频检测应用场景之外,例如网络音视频资源审核,例如微信发布语音视频信息,平台后台会对这些数据进行审核;另外公安技侦通过技术手段来侦查网络、电话犯罪行为;第三个是呼叫中心,传统呼叫中心会产生大量的电话录音,很多行业会对这些录音进行录音质检,从这些录音中提取业务开展的情况;最后一个是电信安全,主要是以关键词检索的手段来防止电信诈骗。 二、音频检测采用的技术手段 音频可以分为有内容和无内容两种:说话内容相关的包括说了什么?(涉政、涉黄、涉赌还是广告信息),另外还可以从说话内容来判断语种以及说话人的辨识;此外还有与说话内容无关的信息,例如特定录音片段、歌曲旋律、环境音等等。 针对不同的数据类型有不同的检测技术。针对说话内容有语音识别、关键词检索等;针对语种的判别有语种识别的技术;针对说话人的识别有声纹识别技术;针对说话内容无关的通常采用音频比对的技术来进行检测。 语音识别的关键技术——声学模型 语音识别的声学模型主要有以下两种:混合声学模型和端到端的声学模型。 混合声学模型通常是隐马尔科夫模型结合混合高斯、深度神经网络、深度循环神经网络以及深度卷积神经网络的一个模型。 端到端声学模型目前有两大类,一是连接时序分类—长短时记忆模型,二是注意力模型。 声学模型——混合高斯—隐马尔科夫模型
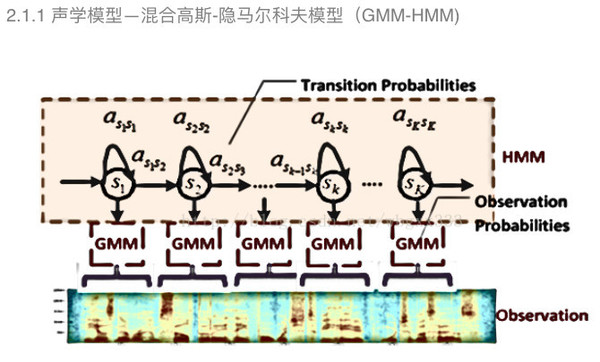
混合高斯—隐马尔科夫模型是根据语音的短时平稳性采用采用隐马尔科夫模型对三因子进行建模。图中显示的是,输入语音参数通过混合高斯模型计算每一个隐马尔科夫模型状态的后验概率,然后隐马尔可夫模型转移概率来描述状态之间的转移。 混合高斯—隐马尔科夫模型是出现最早应用最久远的模型。 声学模型——深度神经网络—隐马尔科夫模型
|