|
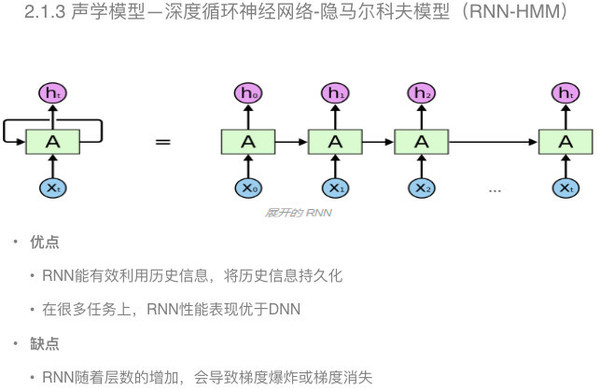
混合神经网络—隐马尔科夫模型是将混合高斯模型用深度神经网络进行替代,但是保留了隐马尔科夫的结构,对于输入端的扩帧和深度神经网络的非线性变换,识别率可以得到很大的提升。 声学模型——深度循环神经网络—隐马尔科夫模型 前面的深度神经网络对历史信息的建模只是通过在输入端扩帧实现的,但对历史信息的建模作用是有限的。
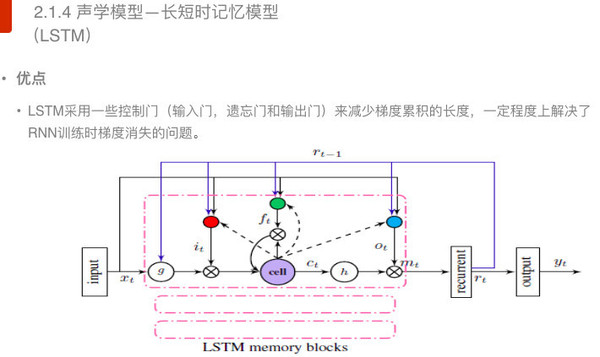
在深度循环神经网络中,对输入的历史信息可以进行有效的建模,可以做大限度的保留历史信息。根据现有的实验结果来看,在很多任务上,深度循环神经网络性能表现要由于深度神经网络。 当然,深度循环神经网络也存在一些缺点。例如,在训练的时候,会出现梯度爆炸和梯度消失的问题。 那么如何有限解决梯度爆炸和梯度消失的问题呢?学者又引入了一种长短时记忆模型。 声学模型——长短时记忆模型
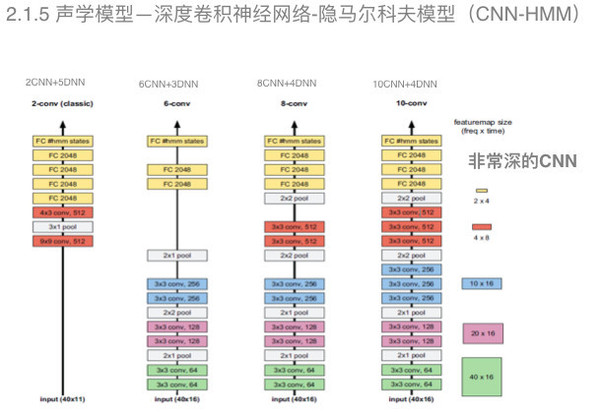
长短时记忆模型采用控制门(包括输入门、遗忘门和输出门)将梯度累积变成梯度累加,在一定程度上可以解决深度循环神经网络训练时梯度消失的问题。 声学模型——深度卷积神经网络—隐马尔科夫模型 上面提到的深度循环神经网络能够有效地对历史信息进行建模,但是它存在计算量太大的问题,特别是为了减少这种梯度消失又引入了长短时记忆模型之后,计算的信息量有加剧。应对这一难题,业界又引入了深度卷积神经网络模型。
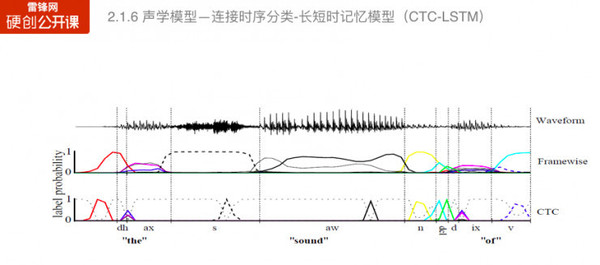
这种模型在图像识别领域和语音识别领域都得到了显著的效果。 在语音识别领域,我们可以从图中可以看出,一共有四种深度神经网络的模型结构,随着深度的增加可以有效地提升声学模型的构建能力。 声学模型——连接时序分类—长短时记忆模型 前面提到的都是基于混合模型,以隐马尔科夫模型来构建转换概率的模型。
在训练过程中,如果要用到高斯混合模型进行强制对齐结果的训练。针对这个问题,也有学则提出了不需要强制对齐的训练方法,例如连接时序分类(CTC),这种方法可以有效加速解码速度。 声学模型——注意力模型
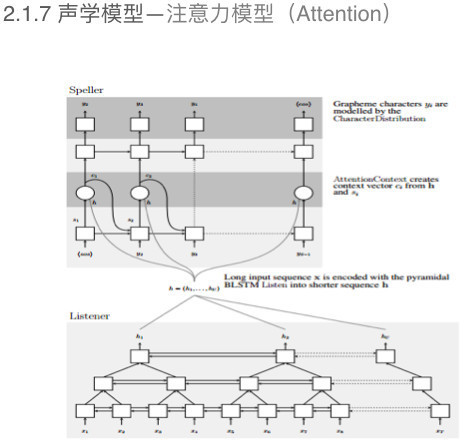
另外一种不需要强制对齐的训练方法是注意力模型的训练方法(如上图)。 语言模型 语言模型——N-Gram
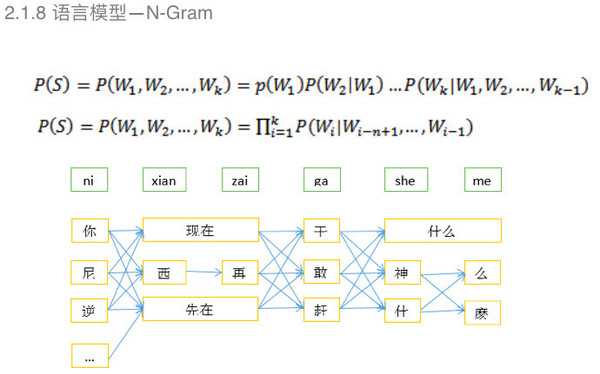
基于N-Gram的特点是每个词出现的概率,之和前面第N-1个词有关,整句话出现的概率是每个词出现的概率的乘积。 N-Gram有一个缺点,由于数据稀缺性需要进行一个平滑算法,然后得到后验概率。 语言模型——DNN-Gram
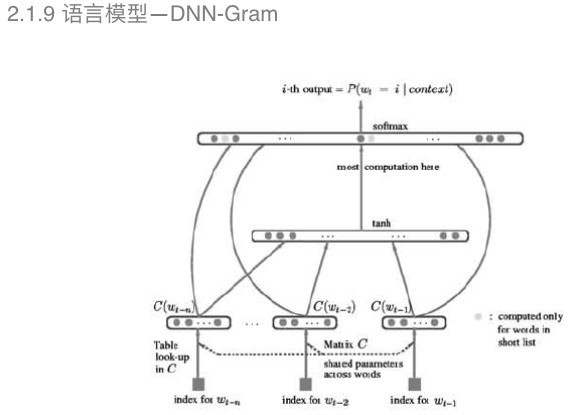
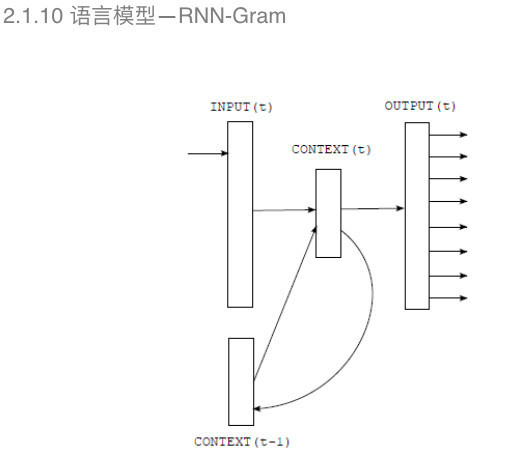
DNN-Gram把深度神经网络引入可以有效地克服平滑算法的误差。例如图中显示的,通过深度神经网络构建语音性不需要平滑算法的处理。 语言模型——RNN-Gram 和声学模型一样,构建语言模型也需要对历史信息进行训练建模,在声学模型中提到的深度循环神经网络在这里也有应用。 基于深度神经网络的语言模型每个词出现的概率和N-Gram一样,只是和向前的第N-1个词有关,但实际上,每个词出现的频率和之前所有词都有相关性,因此需要引入历史信息进行训练建模。
所以在这里加入了RNN-Gram进行语言模型的构建。 近几年,语音识别的声学模型和语言模型都得到了很大的提高。2016年,微软的语音识别团队宣称在swithboard数据集上超过了人类,atv,swithboard数据集是一个以口语为主的训练测试数据集,包含了大量的副语言,所以用这种数据集进行语音识别测试具有一定的挑战性。 (责任编辑:本港台直播) |