|
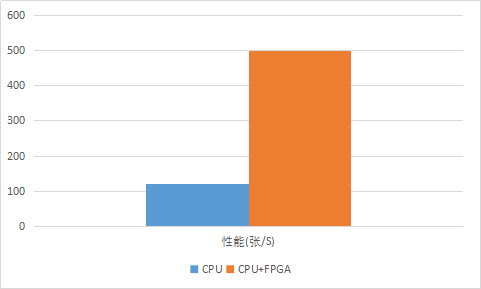
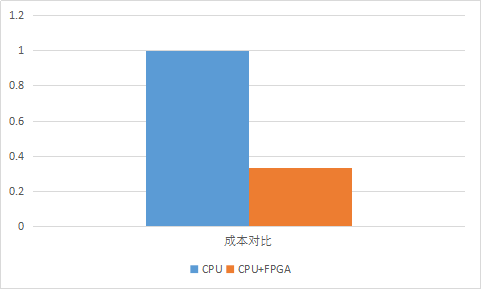
为了达到最好的计算性能就是要尽可能地让FPGA内的在每一个时钟周期都进行有效地工作。为了达到这个目标,CONV模块和后面的ReLU/Norm/Pooling必须能异步流水线进行。Kernel的存储也要有两个存储空间,能对系数进行乒乓加载。另外,由于计算是下一层的输入依赖于上一层的输出,而数据计算完成写回DDR时需要一定时间,依次应该通过交叠计算两张图片的方式(Batch=2)将这段时间通过流水迭掉。 要选择合适的架构,是计算过程中Data和Kernel只要从DDR读取一次,否则对DDR带宽的要求会提高。 3.3 性能及效益 如图3.9所示采用FPGA异构计算之后,FPGA异构平台处理性能是纯CPU计算的性能4倍,而TCO成本只是纯CPU计算的三分之一。本方案对比中CPU为2颗E5-2620,FPGA为Virtex-7 VX690T,这是一个28nm器件,如果采用20nm或16nm的器件会得到更好的性能。
图3.9 计算性能对比
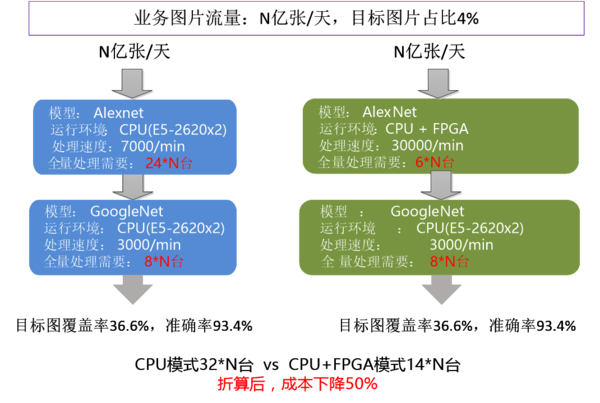
图3.10 归一化单位成本对比 图3.11为实际业务中利用FPGA进行加速的情况,由图中数据可知FPGA加速可以有效降低成本。
图3.11 某实际业务中的性能和成本对比 参考文献 [1] Alex Krizhevsky. ImageNet Classification with Deep Convolutional Neural Networks [2] C. Zhang, et al. Optimizing FPGA-based accelerator design for deep convolutional neural networks. In ACM ISFPGA 2015. [3] P Gysel, M Motamedi, S Ghiasi. Hardware-oriented Approximation of Convolutional Neural Networks. 2016. [4] Song Han,Huizi Mao,William J. Dally.DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFMAN CODING. Conference paper at ICLR,2016 (责任编辑:本港台直播) |