|
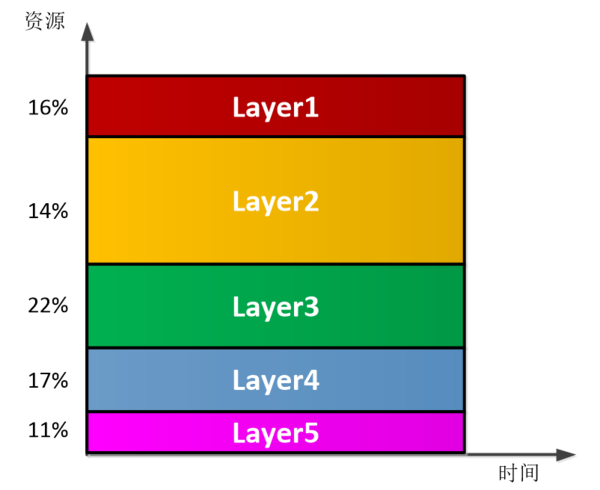
Layer并行模式:如图3.2所示,按照每个layer的计算量分配不同的硬件资源,在FPGA内同时完成所有layer的计算,计算完成之后将计算结果返回CPU。优点是所有的计算在FPGA中一次完成,不需要再FPGA和DDR DRAM直接来回读写中间结果,节省了的DDR带宽。缺点就是不同layer使用的资源比较难平衡,且layer之间的数据在FPGA内部进行缓冲和格式调整也比较难。另外,这种模式当模型参数稍微调整一下(比如说层数增加)就能重新设计,灵活性较差。
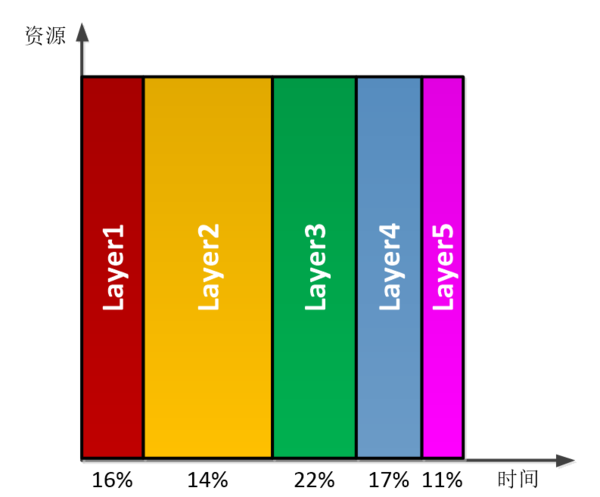
图3.2 layer并行模式下资源和时间分配示意图 Layer串行模式:如图3.3所示,在FPGA中只实现完成单个layer的实现,不同layer通过时间上的复用来完成。优点是在实现时只要考虑一层的实现,数据都是从DDR读出,计算结果都写回DDR,数据控制比较简单。缺点就是因为中间结果需要存储在DDR中,提高了对DDR带宽的要求。
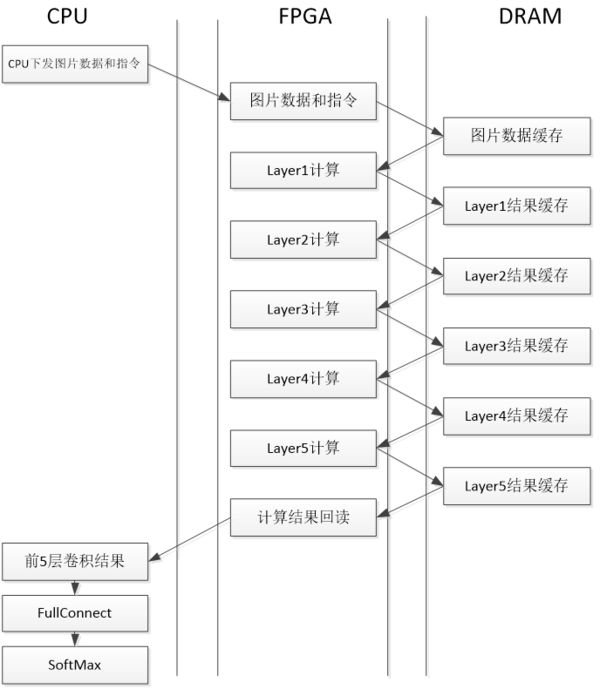
图3.3 layer并行模式下资源和时间分配示意图 我们的设计采用了是Layer串行的模式,数据在CPU、FPGA和DDR直接的交互过程如图3.4所示。
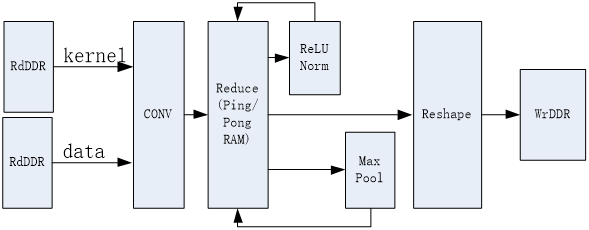
图3.4 计算流程图 3.2.3 计算单个Layer的PM(Processing Module)设计 如图3.5所示,数据处理过程如下,所有过程都流水线进行: Kernel和Data通过两个独立通道加载到CONV模块中; CONV完成计算,并将结果存在Reduce RAM中; (可选)如果当前layer需要做ReLU/Norm,将ReLU/Norm做完之后写回Reduce RAM中; (可选)如果当前layer需要做Max Pooling,将Max做完之后写回Reduce RAM中; 将计算结果进行格式重排之后写回DDR中。
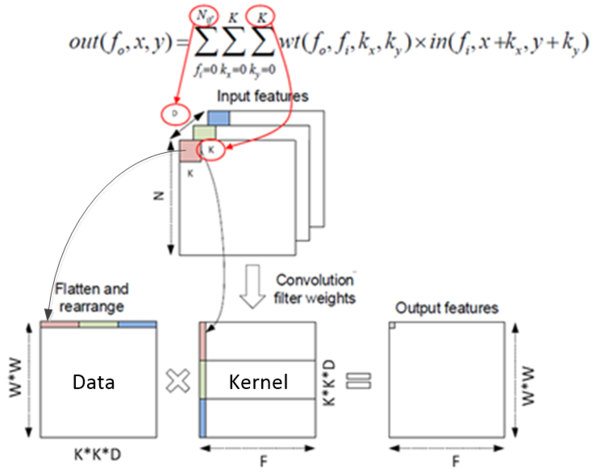
图3.5 Processing Module的结构框图 3.2.4 CONV模块的设计 在整个PM模块中,直播,最主要的模块是CONV模块,CONV模块完成数据的卷积。 由图3.6所示,卷积计算可以分解成两个过程:kernel及Data的展开和矩阵乘法。 Kernel可以预先将展开好的数据存在DDR中,因此不需要在FPGA内再对Kernel进行展开。Data展开模块,主要是将输入的feature map按照kernel的大小展开成可以同kernel进行求内积计算的矩阵。数据展开模块的设计非常重要,不仅要减小从DDR读取数据的数据量以减小DDR带宽的要求,还要保证每次从DDR读取数据时读取的数据为地址连续的大段数据,以提高DDR带宽的读取效率。
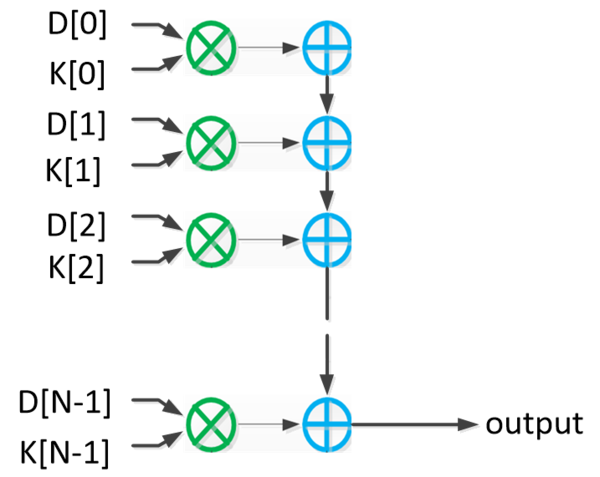
图3.6 卷积过程示意图 图3.7为矩阵乘法的实现结构,通过串联乘加器来实现,一个周期可以完成一次两个向量的内积,通过更新端口上的数据,可以实现矩阵乘法。
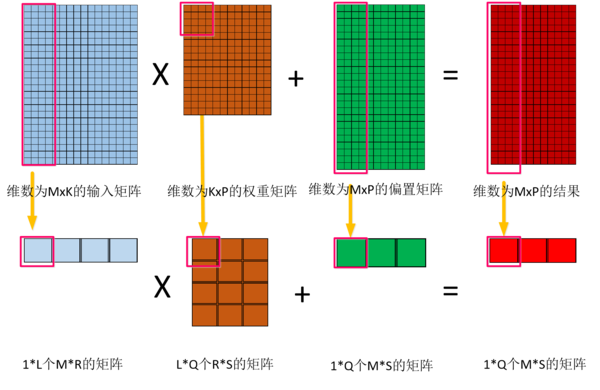
图3.7 矩阵乘法实现结构 展开后的矩阵比较大,FPGA因为资源结构的限制,无法一次完成那么的向量内积,因此要将大矩阵的乘法划分成几个小矩阵的乘加运算。拆分过程如图3.8所示。 假设大矩阵乘法为O= X*W,其中,输入矩阵X为M*K个元素的矩阵;权重矩阵W为K*P个元素的矩阵;偏置矩阵O为M*P个元素的矩阵;
图3.8 大矩阵乘法的拆分过程 R = K/L,如果不能整除输入矩阵,权重矩阵和偏置通过补零的方式将矩阵处理成可以整除; S = P/Q,如果不能整除将权重矩阵和偏置矩阵通过补零的方式将矩阵处理成可以整除; 3.2.5实现过程的关键点 决定系统性能的主要因素有:DSP计算能力,带宽和片内存储资源。好的设计是将这三者达到一个比较好的平衡。参考文献[2]开发了roofline性能模型来将系统性能同片外存储带宽、峰值计算性能相关联。 (责任编辑:本港台直播) |