|
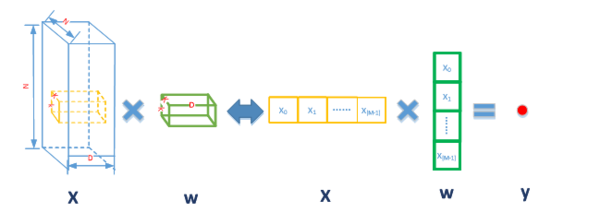
Alexnet的卷积运算是三维的,在神经网络计算公式: y=f(wx+b) 中,对于每个输出点都是三维矩阵w(kernel)和x乘加后加上bias(b)得到的。如下图2.2所示,kernel的大小M=Dxkxk,矩阵乘加运算展开后 y = x[0]*w[0]+ x[1]*w[1]+…+x[M-1]*w[M-1],所以三维矩阵运算可以看成是一个1x[M-1]矩阵乘以[M-1]x1矩阵。
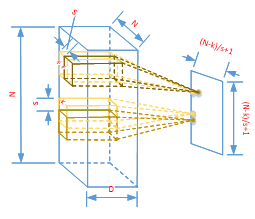
图2.2 Alexnet三维卷积运算 每个三维矩阵kernel和NxN的平面上滑动得到的所有矩阵X进行y=f(wx+b)运算后就会得到一个二维平面(feature map)如图2.3 所示。水平和垂直方向上滑动的次数可以由 (N+2xp-k)/s+1 得到(p为padding的大小),每次滑动运算后都会得到一个点。 a) N是NxN平面水平或者垂直方向上的大小; b) K是kernel在NxN平面方向上的大小kernel_size; c) S是滑块每次滑动的步长stride;
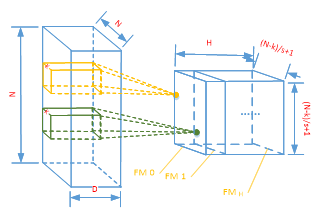
图2.3 kernel进行滑窗计算 Kernel_num 个 kernel 经过运算后就会得到一组特征图,重新组成一个立方体,参数H = Kernel_num,如图2.4所示。这个卷积立方体就是卷积所得到的的最终输出结果。
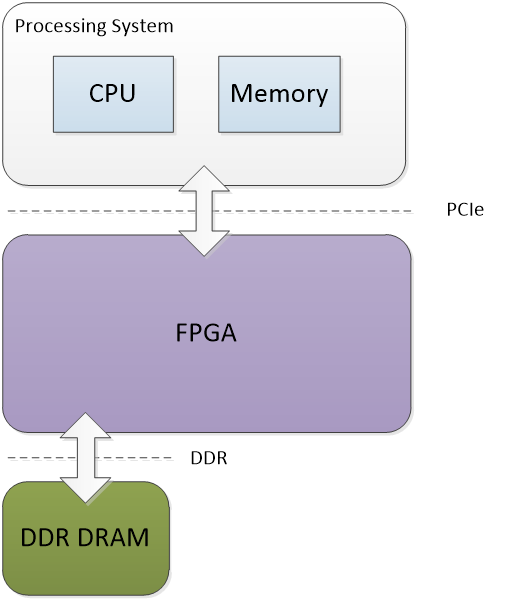
图2.4 多个kernel进行滑窗计算得到一组特征图 3. AlexNet模型的FPGA实现3.1 FPGA异构平台 图3.1为异构计算平台的原理框图,CPU通过PCIe接口对FPGA传送数据和指令,FPGA根据CPU下达的数据和指令进行计算。在FPGA加速卡上还有DDR DRAM存储资源,用于缓冲数据。
图3.1 FPGA异构系统框图 3.2 CNN在FPGA的实现3.2.1 将哪些东西offload到FPGA计算? 在实践中并不是把所有的计算都offload到FPGA,而是只在FPGA中实现前5层卷积层,将全连接层和Softmax层交由CPU来完成,主要考虑原因: 全连接层的参数比较多,计算不够密集,要是FPGA的计算单元发挥出最大的计算性能需要很大的DDR带宽; 实际运用中分类的数目是不一定的,需要对全连阶层和Softmax层进行修改,将这两部分用软件实现有利于修改。 3.2.2 实现模式 Alexnet的5个卷积层,如何分配资源去实现它们,主要layer并行模式和layer串行模式: (责任编辑:本港台直播) |