|
:COO、执行总编、主编、高级编译、主笔、运营总监、客户经理、咨询总监、行政助理等 9 大岗位全面开放。 简历投递:j[email protected] HR 微信:13552313024 新智元为COO和执行总编提供最高超百万的年薪激励;为骨干员工提供最完整的培训体系、高于业界平均水平的工资和奖金。 加盟新智元,与人工智能业界领袖携手改变世界。 【新智元导读】不久前微软DMTK(分布式机器学习工具包)团队在GitHub上开源了性能超越其他boosting工具的LightGBM,在三天之内GitHub上被star了1000+次,fork了200+次。知乎上有近千人关注“如何看待微软开源的LightGBM?”问题,被评价为“速度惊人”,“非常有启发”,“支持分布式”,“代码清晰易懂”,“占用内存小”等。本文邀请了微软亚洲研究院DMTK团队的研究员们为我们撰文解读,教你玩转LightGBM。
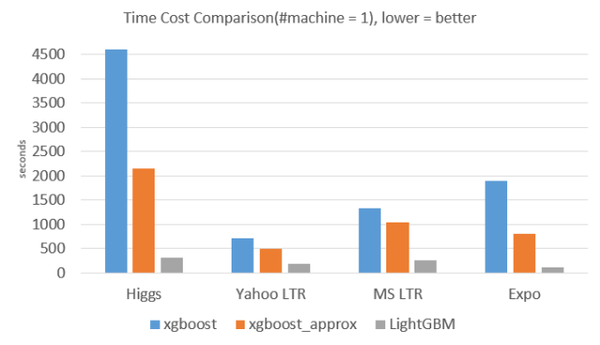
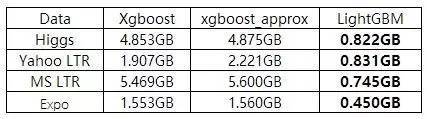
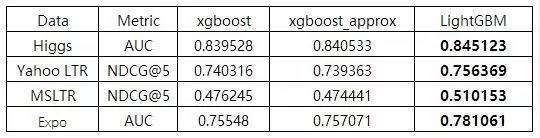
GBDT (Gradient Boosting Decision Tree) 是机器学习中一个长盛不衰的模型,其主要思想是利用弱分类器(决策树)迭代训练以得到最优模型,该模型具有训练效果好、不易过拟合等优点。GBDT在工业界应用广泛,通常被用于点击率预测,搜索排序等任务。GBDT也是各种数据挖掘竞赛的致命武器,据统计Kaggle上的比赛有一半以上的冠军方案都是基于GBDT。 LightGBM (Light Gradient Boosting Machine)(https://github.com/Microsoft/LightGBM)是一个实现GBDT算法的框架,支持高效率的并行训练,并且具有以下优点: 更快的训练速度 更低的内存消耗 更好的准确率 分布式支持,可以快速处理海量数据 从LightGBM的GitHub主页上可以直接看到实验结果: 从下图实验数据可以看出,在Higgs数据集上LightGBM比XGBoost快将近10倍,内存占用率大约为XGBoost的1/6,直播,并且准确率也有提升。在其他数据集上也可以观察到相似的结论。 >>>> 训练速度方面
>>>> 内存消耗方面
>>>> 准确率方面
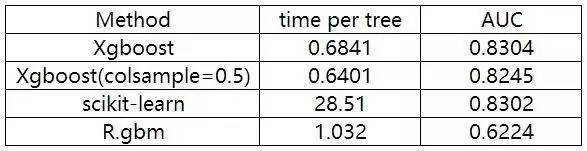
(我们只和xgboost进行对比,因为xgboost号称比其他的boosting 工具都要好,从他们的实验结果来看也是如此。) XGBoost 与其他方法在Higgs-1M数据的比较:
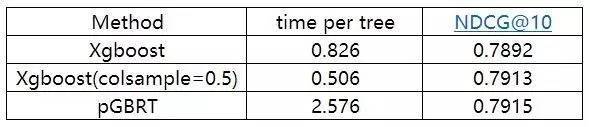
XGBoost 与其他方法在Yahoo LTR数据的比较:
看完这些惊人的实验结果以后,对下面两个问题产生了疑惑: Xgboost已经十分完美了,为什么还要追求速度更快、内存使用更小的模型? 对GBDT算法进行改进和提升的技术细节是什么? 提出LightGBM的动机 常用的机器学习算法,例如神经网络等算法,都可以以mini-batch的方式训练,训练数据的大小不会受到内存限制。 而GBDT在每一次迭代的时候,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。尤其面对工业级海量的数据,普通的GBDT算法是不能满足其需求的。 LightGBM提出的主要原因就是为了解决GBDT在海量数据遇到的问题,让GBDT可以更好更快地用于工业实践。 改进的细节 1. Xgboost是如何工作的? 目前已有的GBDT工具基本都是基于预排序的方法(pre-sorted)的决策树算法(如 xgboost)。这种构建决策树的算法基本思想是: 首先,对所有特征都按照特征的数值进行预排序。 其次,在遍历分割点的时候用O(#data)的代价找到一个特征上的最好分割点。 最后,找到一个特征的分割点后,将数据分裂成左右子节点。 这样的预排序算法的优点是能精确地找到分割点。 缺点也很明显: (责任编辑:本港台直播) |