|
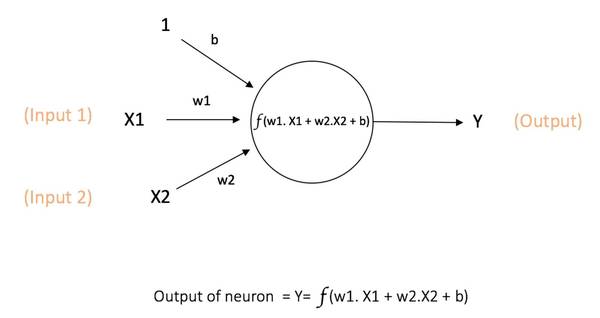
参与:Leonardo Luke 本文对多层感知器和反向传播进行入门级的介绍。作者 Ujjwal Karn 在机器学习领域有三年的从业和研究经验,对深度学习在语音和视觉识别上的应用非常感兴趣。 人工神经网络是一种计算模型,启发自人类大脑处理信息的生物神经网络。人工神经网络在语音识别、计算机视觉和文本处理领域取得了一系列突破,让机器学习研究和产业感到了兴奋。在本篇博文中,我们将试图理解一种称为「多层感知器(Multi Layer Perceptron)」的特定的人工神经网络。 单个神经元 神经网络中计算的基本单元是神经元,一般称作「节点」(node)或者「单元」(unit)。节点从其他节点接收输入,或者从外部源接收输入,然后计算输出。每个输入都辅有「权重」(weight,即 w),权重取决于其他输入的相对重要性。节点将函数 f(定义如下)应用到加权后的输入总和,如图 1 所示:
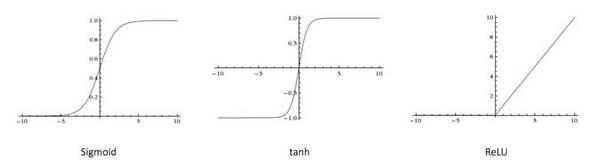
图 1:单个神经元 此网络接受 X1 和 X2 的数值输入,其权重分别为 w1 和 w2。另外,还有配有权重 b(称为「偏置(bias)」)的输入 1。我们之后会详细介绍「偏置」的作用。 神经元的输出 Y 如图 1 所示进行计算。函数 f 是非线性的,叫做激活函数。激活函数的作用是将非线性引入神经元的输出。因为大多数现实世界的数据都是非线性的,我们希望神经元能够学习非线性的函数表示,所以这种应用至关重要。 每个(非线性)激活函数都接收一个数字,并进行特定、固定的数学计算 [2]。在实践中,可能会碰到几种激活函数: Sigmoid(S 型激活函数):输入一个实值,输出一个 0 至 1 间的值 σ(x) = 1 / (1 + exp(?x)) tanh(双曲正切函数):输入一个实值,输出一个 [-1,1] 间的值 tanh(x) = 2σ(2x) ? 1 ReLU:ReLU 代表修正线性单元。输出一个实值,并设定 0 的阈值(函数会将负值变为零)f(x) = max(0, x) 下图 [2] 表示了上述的激活函数
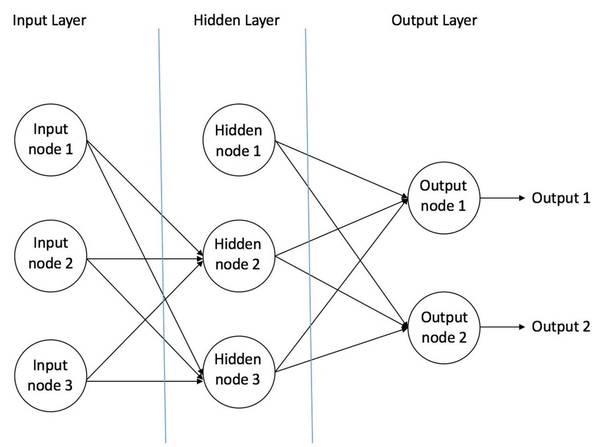
图 2:不同的激活函数。 偏置的重要性:偏置的主要功能是为每一个节点提供可训练的常量值(在节点接收的正常输入以外)。神经元中偏置的作用,详见这个链接: 前馈神经网络 前馈神经网络是最先发明也是最简单的人工神经网络 [3]。它包含了安排在多个层中的多个神经元(节点)。相邻层的节点有连接或者边(edge)。所有的连接都配有权重。 图 3 是一个前馈神经网络的例子。
图 3: 一个前馈神经网络的例子 一个前馈神经网络可以包含三种节点: 1. 输入节点(Input Nodes):输入节点从外部世界提供信息,总称为「输入层」。在输入节点中,不进行任何的计算——仅向隐藏节点传递信息。 2. 隐藏节点(Hidden Nodes):隐藏节点和外部世界没有直接联系(由此得名)。这些节点进行计算,并将信息从输入节点传递到输出节点。隐藏节点总称为「隐藏层」。尽管一个前馈神经网络只有一个输入层和一个输出层,但网络里可以没有也可以有多个隐藏层。 3. 输出节点(Output Nodes):输出节点总称为「输出层」,负责计算,并从网络向外部世界传递信息。 在前馈网络中,信息只单向移动——从输入层开始前向移动,然后通过隐藏层(如果有的话),再到输出层。在网络中没有循环或回路 [3](前馈神经网络的这个属性和递归神经网络不同,后者的节点连接构成循环)。 下面是两个前馈神经网络的例子: 1. 单层感知器——这是最简单的前馈神经网络,不包含任何隐藏层。你可以在 [4] [5] [6] [7] 中了解更多关于单层感知器的知识。 2. 多层感知器——多层感知器有至少一个隐藏层。我们在下面会只讨论多层感知器,因为在现在的实际应用中,它们比单层感知器要更有用。 多层感知器 多层感知器(Multi Layer Perceptron,即 MLP)包括至少一个隐藏层(除了一个输入层和一个输出层以外)。单层感知器只能学习线性函数,而多层感知器也可以学习非线性函数。
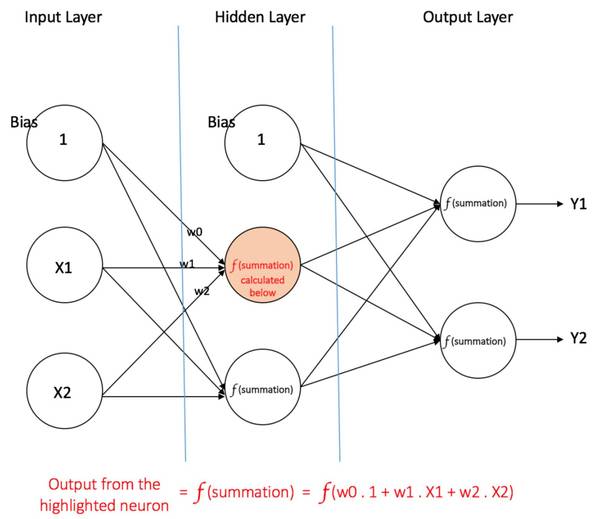
图 4:有一个隐藏层的多层感知器 图 4 表示了含有一个隐藏层的多层感知器。注意,所有的连接都有权重,但在图中只标记了三个权重(w0,,w1,w2)。 (责任编辑:本港台直播) |