|
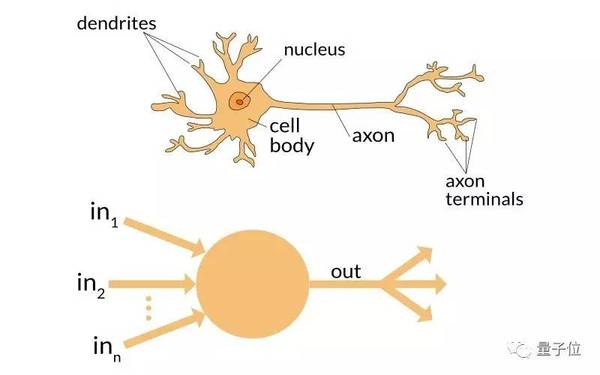
王瀚森 编译自 Analytics Vidhya 量子位 出品 | 公众号 QbitAI 人工智能,深度学习,机器学习……不管你在从事什么工作,都需要了解这些概念。否则的话,三年之内你就会变成一只恐龙。 —— 马克·库班 库班的这句话,乍听起来有些偏激,但是“话糙理不糙”,我们现在正处于一场由大数据和超算引发的改革洪流之中。 首先,我们设想一下,如果一个人生活在20世纪早期却不知电为何物,是怎样一种体验。在过去的岁月里,他已经习惯于用特定的方法来解决相应的问题,霎时间周围所有的事物都发生了剧变。以前需要耗费大量人力物力的工作,现在只需要一个人和电就能完成了。 而在现在的背景下,机器学习、深度学习就是新的“电力”。 所以呢,如果你还不了解深度学习有多么强大,不妨就从这篇文章开始。在这篇文章中,作者Dishashree Gupta为想了解深度学习的人,罗列并解释了25个这一领域最常用的术语。 这25个术语被分成三组: 神经网络中的基础概念(包含常用的一些激活函数) 卷积神经网络 递归神经网络 基础概念: (1) 神经元(Neuron)正如我们大脑中的基本组成单元,神经元是组成神经网络的基础结构。设想一下当接触到新的信息时,我们的身体会对其进行处理,最后产生一些特定的反应。 相似地,在神经网络中,在收到输入的信号之后,神经元通过处理,然后把结果输出给其它的神经元或者直接作为最终的输出。
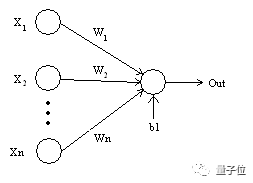
(2) 加权/权重(Weights) 当输入信号进入到神经元后,会被乘以相应的权重因子。举例来说,假设一个神经元有两个输入信号,那么每个输入将会存在着一个与之相应的权重因子。在初始化网络的时候,这些权重会被随机设置,然后在训练模型的过程中再不断地发生更改。 在经过训练后的神经网络中,一个输入具有的权重因子越高,往往意味着它的重要性更高,对输出的影响越大。另一方面,当权重因子为0时意味着这个输入是无价值的。 如下图所示,假设输入为a,相应的权重为W1。那么通过赋权节点后相应的输入应变为a*W1。
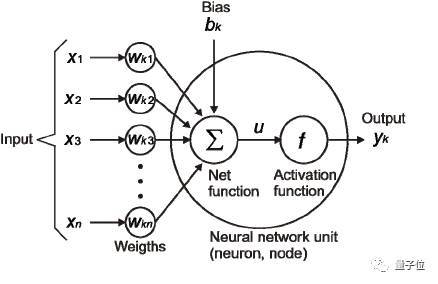
(3) 偏置/偏倚(Bias) 除了权重之外,输入还需要经过另外一种线性处理,叫做偏置。通过把偏置b与加权后的输入信号a*W1直接相加,开奖,以此作为激活函数的输入信号。 (4) 激活函数 之前线性处理之后的输入信号通过激活函数进行非线性变换,从而得到输出信号。即最后输出的信号具有f(a*W1+b)的形式,其中f()为激活函数。 在下面的示意图中, 设X1…Xn等n个输入分别对应着权重因子Wk1…Wkn以及相应的偏置b1…bn。我们把输入Xi乘以对应的权重因子Wki再加上bi的结果称为u。 u=∑w*x+b 这个激活函数f是作用在u上的,也就是说这个神经元最终的输出结果为yk = f(u)
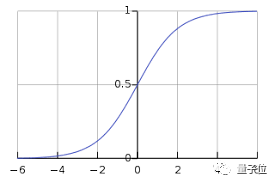
接下来我们讲一讲常用的一些激活函数:Sigmoid函数, 线性整流函数(ReLU) 和 softmax函数 (a) Sigmoid函数 作为最常用的激活函数之一,它的定义如下:
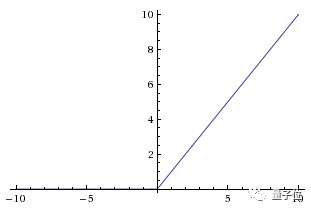
△来源:维基百科 sigmoid函数为值域在0到1之间的光滑函数,当需要观察输入信号数值上微小的变化时,与阶梯函数相比,平滑函数(比如Sigmoid函数)的表现更好。 (b) 线性整流函数(ReLU-Rectified Linear Units) 近来的神经网络倾向于使用ReLU替代掉sigmoid函数作为隐层的激活函数,它的定义如下: f(x) = max(x,0). 当x大于0时,函数输出x,其余的情况输出为0。函数的图像是:
△来源:cs231n 使用ReLU函数的好处是,对于所有大于0的输入,导数是恒定的,这能够加快训练网络的速度。 (c) softmax函数 softmax激活函数通常应用在分类问题的输出层上。 (责任编辑:本港台直播) |