|
安妮 编译自 HackerNoon 量子位 出品 | 公众号 QbitAI 现在,很多产品经理、技术经理和设计师都开始研究机器学习。但机器学习对产品的设计、支持、管理或规划会产生怎样的影响?可能很多产品经理都不知道如何回答这个问题。 机器学习(Machine Learning, ML)可能是个“坑”。非技术人员需要的是足够的知识广度来设计机器学习产品,而不是专业的机器学习技术公开课。就如同你只是想学习开车,却报了一门“内燃机引擎”的课——学了它你也并不能学会如何开车!只能说”That’s too much for you”。 Part 1: 不扯数学,就说机器学习 机器学习系统自动从数据中学习程序。 ——Pedro Domingos 确实,机器学习是一种在你都不知如何运作下创建的一种程序。与传统创建程序不同的是,我们不需要为它的每一步编写代码。事实上,你需要给它创建一个数据模型,atv,即“学习算法”(Learning algorithm),而算法的核心就是一个有关“错误”的概念——学习算法试图将错误概率最小化。 机器学习的学习任务可以大致分为两类:“监督学习”(supervised learning)和“无监督学习”(unsupervised learning)。如何在产品中区分它们?我们来看几个例子。 无监督学习:数据模式的学问 系统将使用无标记信息的数据,也不会被告知“正确答案”,为了探索数据并找到内部结构。无监督学习对用户数据的处理效果就比较好。 Foursquare的“本周热门”(Trending this Week)就是一个很好的例子。Foursquare是纽约一家基于用户地理位置信息(LBS)的手机服务网站,鼓励手机用户同他人分享自己当前所在的地理位置等信息。讲道理,Foursquare获取的用户停留数据并没有被系统标记,但系统通过无监督学习可以将地点聚类而划分出热门地点。基于用户数据生成本周热门地点信息,推荐给其他用户。对它来说,数据模式创造出了餐厅流行趋势。
监督学习:预测结果的学问 监督学习拥有被标记信息,它会试图对结论进行试验和预测,就像垃圾邮件检测的模式一样。 简单来讲,你首先需要为很多邮件做标记——它们是否为垃圾邮件。之后将这些被标记的邮件存入算法,再用新邮件进行测试。算法的目标是将可能的错误概率最小化。如果算法认为这是一封垃圾邮件,则将它带入用户邮箱的垃圾箱里。
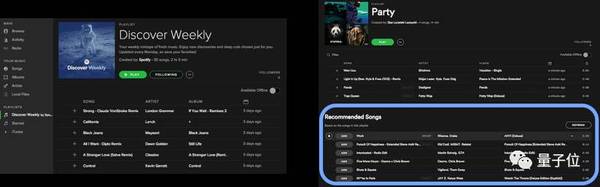
产品应用中并不那么好区分 虽然上述例子中可以看到监督学习和无监督学习有一定的差别,直播,但很多情况下两者并不能被明显区分。我们可以来做个测试——你能推测出音乐平台Spotify中的“每周发现”(Discover Weekly)和“推荐歌曲”(Recommended Songs)功能所应用的算法有何不同吗?两者都是为你推荐的歌单,但它们的的确确是不同的算法。
“每周发现”可以算作一种监督学习,机器学习记录你所听过的歌曲,并以此当成样例来预测你可能喜欢的歌曲。而“推荐歌曲”更像是一种无监督学习任务,算法在数百万张播放列表中寻找共现(co-occurrence)模式,为你推荐与你口味相似的其他人歌单中出现频率较高的歌曲。不得不说,这真是一个水灵灵的举例。 给你一筐可能用到的产品术语 数据学家经常会用一些术语来描述机器学习中遇到的问题。要不我们来做一道填空题:你建立的产品是解决? 1.帮助用户搜索到最合心意的选项?你说的是排序问题(ranking problem)吧。谷歌、微软必应、甚至是Twitter的搜索引擎都致力于此——试图找到并解决你当前提出的问题,并把最适合的那个置于列表最上面。 2.在用户没有进行明确搜索的情况下,给他们推荐可能感兴趣的话题?这是推荐问题(recommendation problem)。Netflix、Spotify还有Twitter——都是通过推荐内容来激发用户使用兴趣。 3.想搞清楚一件属于何种类型?对了,这就是分类问题(Classification problem)。Gmail 的反垃圾邮件系统、Facebook上的照片(人脸识别系统)就是很好的例子。 4.预测数值?可能你想说的是回归问题(regression problem)。比如预测机票价格在两小时内的波动,这已经是Google在半年前推出的产品了。 (责任编辑:本港台直播) |