|
【启航期 85 折票价倒计时 2 天】“3·15”晚会让人脸识别技术一夜走红。如今中国的人脸识别技术发展到什么阶段,有什么商业应用?3月27日新智元 AI 技术峰会,汇聚商汤徐立、云从周曦、阿里华先胜、海康威视蒲世亮等国内人脸识别技术大牛,技术领袖论坛更有360首席科学家颜水成出席,直击人脸识别真相,点击“阅读原文”抢票。 【新智元导读】对话生成模型已引起了学术界和工业界的广泛关注。在大数据的支撑下,对话生成模型的效果尚可。但在实际工作中,可能需要构建特定领域的对话生成模型。而特定领域的聊天语料一般都是较为稀缺的,无法满足训练对话生成模型的需求。适应的对话生成模型利用了全领域的对话数据(即从互联网上可以直接收集到的大规模对话数据)帮助训练特定领域的对话生成模型。这一方法让对话生成模型向实际应用中的智能聊天机器人中更近了一步。 背景介绍 对话生成模型是最近几年才被提出的模型,该模型从提出开始便迅速的成为了学术界和工业界的研究热点。 提到对话生成模型,我们不得不先提到Sutskever和Cho两个大神。其实这两个人没有一个是研究对话生成模型的。那我们为什么要提到这两个人呢?因为现在大多数对话生成模型的框架都是以这两个人的工作为基础的。这两个人到底是干什么的呢?他们是研究机器翻译的。他们两个人来自于不同的团队,但都在2014年发表了广受业界关注的文章。他们的文章中都提出了用RNN Encoder Decoder的框架去做机器翻译。这个框架刚一提出,瞬间就火了,为什么呢?因为它相比于传统的方法效果提升了很多。而且它是端到端的,就是说在这个框架下不需要过多的人工参与,只要将一句话输入到RNN Encoder-Decoder的网络中,就可以自动的生成一句话,省去了人工提取特征这个烦人的操作。 之后Cho大神又和Bahdanau合作提出了Attention based Encoder Decoder。这个模型把机器翻译的效果又提升了一大截,特别是对长句子的效果要比原有的RNN Encoder Decoder好很多。这下RNN一时间占领了自然语言处理领域,几乎所有研究自然语言处理任务的人都开始研究用RNN解决他们的问题。 对话生成模型也是在这个RNN的大潮下被提出的。对话生成和机器翻译的输入和输出都是句子。因此,人们很容易的想到了将Sutskever和Cho两个大神的思路直接套用到对话生成模型上,然后在此基础上再做一些改进。 2015年,有关对话生成模型的论文井喷似的产生。其中华为诺亚方舟实验室在这方面做了比较突出的贡献,他们在Attention based Encoder Decoder的基础上提出了Neural Response Machine。个人认为他们工作的主要贡献是给研究者们指明了一个新的研究方向——对话生成模型研究。同时他们给出了一个现在公认有效的评估方式——人工评测。 大多数研究对话生成模型的团队都是从互联网上收集了大规模的对话语料作为训练数据。在大数据的支撑下,直播,对话生成模型的效果尚可。在我们的实际工作中,可能需要构建特定领域的对话生成模型。比如:微信有很多公众号,我们可以给每个公众号搭建一个聊天机器人,但是每个公众号都有他们特定的领域,而特定领域的聊天语料一般都是较为稀缺的,无法满足训练对话生成模型的需求。那么怎么办呢?难道对话生成模型就不能用到特定领域的聊天机器人中了吗? 对话生成模型那么好,我们怎么可能轻易放弃呢?数据量少就想办法呗,万一找出一个解决办法我们是不是也能像Sutskever和Cho两个大神一样火一次。上文提到了大多数研究对话生成模型的团队都是从互联网上收集了大规模的对话语料数据作为训练数据,这些数据虽然不是特定领域的对话数据,但起码也是对话数据啊,我们是不是可以想个办法利用这部分数据帮助特定领域的对话生成模型的训练呢。 在我们的冥思苦想之下,终于看到了一点曙光。我们发现了秘密武器——适应的对话生成模型。下面两章我们先介绍一下对话生成模型是怎么实现,之后介绍一下适应性对话生成模型的原理。 对话生成模型
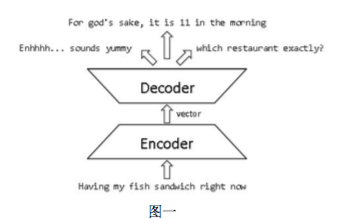
如图一所示,对话生成模型一般采用RNN Encoder Decoder的框架。Encoder将输入的问题编码到一个隐向量中,Decoder负责对这个隐向量进行解码,得到最后输出的答案。RNN Encoder Decoder可以看做是最大化给定输入问题条件下输出答案的条件概率。假设我们有一个语料集,其中表示输入的问题,表示输出的答案,表示语料中问题与答案对的个数,那么对话模型的目标函数就可以表示为:
适应的对话生成模型 (责任编辑:本港台直播) |