|
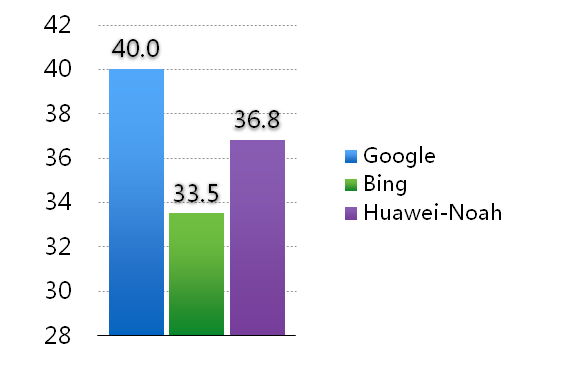
【启航期 85 折票价倒计时 4 天】3月13日晚,英特尔以153 亿美元的价格强势收购自动驾驶汽车摄像头供应商 Mobileye,消息传出震惊业界。这是英特尔自动驾驶部门成立后的第一笔重大收购,智能时代英特尔重拳出击。3月27日,英特尔与新智元共同在北京举办 AI 技术峰会,届时英特尔中国研究院院长宋继强将登台阐释 PC 时代的王者如何拥抱智能时代。近距离了解进击 AI 的英特尔,点击“阅读原文”抢票。 【新智元导读】华为诺亚方舟实验室在他们一篇被 AAAI 2017 录用的论文里提出了一个新的神经机器翻译(NMT)模型,引入基于重构的忠实度指标,结果显示该模型确实有效提高了机器翻译的表现。华为诺亚方舟实验室的研究人员表示,他们的 NMT 技术与谷歌持平。 论文地址:https://arxiv.org/pdf/1611.01874.pdf 基于深度学习的机器翻译,简称深度机器翻译近两年来取得了惊人的进展,翻译的准确度综合评比已经超过传统的统计机器翻译,研究单位主要有蒙特利尔大学[1,2],斯坦福大学[3,4],清华大学[5,6],谷歌[3,7,8],微软[9]和百度[5,10],以及华为诺亚方舟实验室[11-13],竞争异常激烈。 最近谷歌发表论文[8],介绍了他们最新的研究成果,引起业界广泛关注,他们的系统主要采用了蒙特利尔大学、斯坦福大学、清华大学、以及华为诺亚方舟实验室的技术,以及一些工程上的优化,其最大特点是使用了大规模的训练数据。 我们在同一测试数据集上对谷歌、微软必应、及诺亚的系统做了评测(百度翻译因为直接记录了该测试集,无法直接比较),结果如下图所示。指标是业界标准 BLEU 点,一般来说人的 BLEU 值在50-70之间。
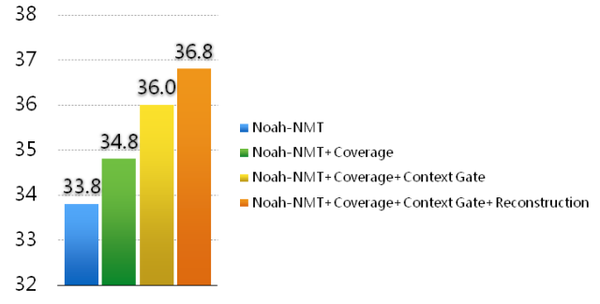
谷歌系统比诺亚系统高大概3个 BLEU 点。我们分析,这主要是因为谷歌系统集成了业界多种最新技术(包括诺亚的 Coverage 技术),以及使用了更大的训练数据集(据说数亿句对 vs. 一百万句对)。其实他们在方法上的创新并不多。可以说诺亚的基本技术与谷歌是持平的。 诺亚最近提出了三个方法,从不同角度提高深度机器翻译的精度。 在 NIST 中英新闻翻译任务上,这三个方法将译文的 BLEU 分数从33.8逐步提高到36.8,取得了9%的提升,达到了业界领先水平。三个工作分别被自然语言处理和人工智能顶级会议及期刊 ACL 2016, TACL 2017 和 AAAI 2017 录用。第一个方法在业界得到广泛好评,也被谷歌采用。下图总结了诺亚的方法对深度翻译的提高。
1. 覆盖率(Coverage)机制 [11]:通过记录哪些词已经被翻译了,鼓励系统翻译未被翻译的词。这个方法可以显著减少遗漏翻译和过度翻译的错误数量。 2. 上下文门(Context Gate)方法[12]:在译文生成过程中,实词和虚词对原文信息的依赖是不一样的。该方法通过自动控制原文信息参与生成不同类型译文词的程度,使原文信息更有序、更完整地传输到译文中。 3. 基于重构(Reconstruction)的忠实度指标[13]:以译文重新翻译成原文的程度来衡量译文的忠实度。通过将重构指标引入训练过程,系统可生成更忠于原文的译文。 深度机器翻译并不能包打天下,在训练数据缺乏,以及人的知识加入的条件下,未必能够发挥威力。诺亚正在研究基于EAI思想的机器翻译,旨在将深度翻译与人的知识结合起来,以开发出更好的机器翻译系统。 下面介绍华为诺亚方舟实验室将 BLEU 分数提高到36.8%的基于重构的深度机器翻译方法[13],该论文被 AAAI 2017 录用。 论文标题:基于重构的神经机器翻译
论文地址:https://arxiv.org/pdf/1611.01874.pdf 摘要 虽然端到端的神经机器翻译(NMT)在过去两年中取得了显着的进步,但 NMT 存在一个很大的缺点:由 NMT 系统产生的译文通常缺乏忠实度。有许多观察显示,NMT 倾向于重复翻译一些源词,而忽略了其他词造成误译。为了减轻这个问题,我们提出了一个新的 NMT 框架,即 编码器 - 解码器 - 重构器(encoder-decoder-reconstructor)框架。重构器被结合到 NMT 模型中,目的是设法从输出的目标句子的隐藏层重构输入的源句子,以确保源句子中包含的信息尽可能多地体现在目标译文中。实验证明,我们提出的框架显著提高了 NMT 输出译文的忠实度,并且我们的翻译结果达到当前 NMT 以及统计机器翻译系统的最先进水平。
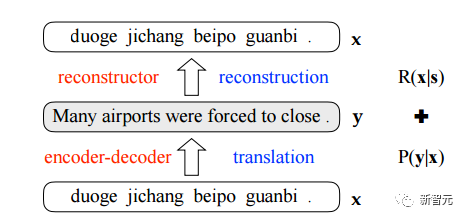
图1:基于重构的 NMT 示例 方法
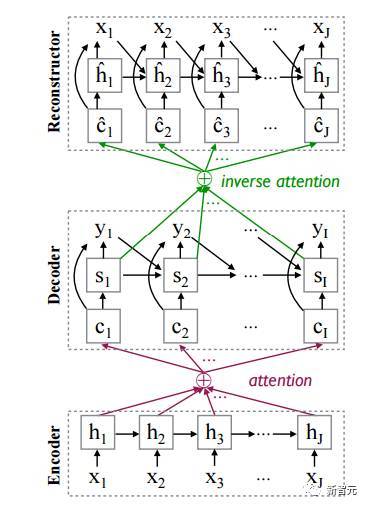
图2:基于重构的 NMT 架构,引入了一个从目标侧的隐藏层映射到原始输入的重构器。 (责任编辑:本港台直播) |