|
这个网络有两点与全连接神经网络不同。首先它不是全连接的。右层的神经元并非连接上全部输入,而是只连接了一部分。这里的一部分就是输入图像的一个局部区域。我们常听说 CNN 能够把握图像局部特征、alphaGO 从棋局局部状态提取信息等等,就是这个意思。这样一来权值少了很多,因为连接就少了。权值其实还更少,因为每一个神经元的9个权值都是和其他神经元共享的。全部个神经元都用这共同的一组9个权值,并且不要偏置值。那么这个神经网络其实一共只有9个参数需要调整。 看了第一节的同学们都看出来了,这个神经网络不就是一个卷积滤波器么?只不过卷积核的参数未定,需要我们去训练——它是一个“可训练滤波器”。这个神经网络就已经是一个拓扑结构特别简单的 CNN 了。 试着用 sobel 算子滤出来的图片作为目标值去训练这个神经网络。给网络的输入是灰度 lena 图,正确输出是经过 sobel 算子滤波的 lena 图,见图4。这唯一的一对输入输出图片就构成了训练集。网络权值随机初始化,训练2000轮。如下图:
图11 从左上到右下依次为:初始随机滤波器输出、每个200轮训练后的滤波器输出(10幅)、最后一幅是 obel 算子的输出,也就是用作训练的目标图像。可以看到经过最初200轮后,神经网络的输出就已经和 sobel 算子的输出看不出什么差别了。后面那些轮的输出基本一样。输入与输出的均方误差 mse 随着训练轮次的变化如下图:
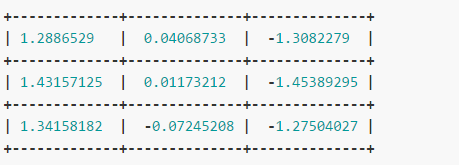
图12 1500轮过后,mse 基本就是0了。训练完成后网络的权值是:
与 sobel 算子比较一下:
注意训练出来的滤波器负数列在右侧而不是左侧。因为用 sobel 算子算卷积的时候也许库函数是把滤波器“反着扣上去”的。这并不重要。关键是一正列、一负列,中间零值列。正/负列值之比近似1:2:1。它就是近似的 sobel 算子。我们以训练神经网络的方式把一个随机滤波器训练成了 sobel 算子。这就是优化的魔力。alphaGO 之神奇的核心也在于此:优化。 在 CNN 中,这样的滤波器层叫做卷积层。一个卷积层可以有多个滤波器,每一个叫做一个 channel,直播,或者叫做一个 feature map。可以给卷积层的输出施加某个激活函数 Sigmoid、tanh 等等。激活函数也构成 CNN 的一层——激活层,这样的层没有可训练的参数。 还有一种层叫做 Pooling 层。它也没有参数,起到降维的作用。将输入切分成不重叠的一些 n×n 区域。每一个区域就包含个值。从这个值计算出一个值。计算方法可以是求平均、取最大 max 等等。假设 n=2,那么4个输入变成一个输出。输出图像就是输入图像的1/4大小。若把2维的层展平成一维向量,后面可再连接一个全连接前向神经网络。 通过把这些组件进行组合就得到了一个CNN。它直接以原始图像为输入,以最终的回归或分类问题的结论为输出,内部兼有滤波图像处理和函数拟合,所有参数放在一起训练。这就是卷积神经网络。 四、举个例子 手写数字识别。数据集中一共有42000个28×28的手写数字灰度图片。十个数字(0~9)的样本数量大致相等。下图展示其中一部分(前100个):
图13 将样本集合的75%用作训练,剩下的25%用作测试。构造一个结构如下图的CNN:
图14 该CNN共有8层(不包括输入层)。它接受784元向量作为输入,就是一幅 28×28 的灰度图片。这里没有将图片变形成 28×28 再输入,因为在CNN的第一层放了一个 reshape 层,它将784元的输入向量变形成 1×28×28 的阵列。最开始那个 1× 表示只有一个 channel,因为这是灰度图像,并没有 RGB 三个 channel。 (责任编辑:本港台直播) |