|
大数据文摘作品,转载请联系 编译团队|寒阳,范玥灿,毛丽,曹翔 现在是机器思考,学习并创造的世界。此外,他们做这些事情的能力会迅速增加,直到在一个明显的未来,他们能处理的问题范围将与人类思想应用的范围一起扩大。 ——赫伯特·西蒙, 1957 2017年1月14日Texas Data Day的大会上,Deep Grammar的联合创始人、CEO、人工智能专家和机器学习专家Jonathan Mugan做了题为《从自然语言处理到人工智能(Deep Learning for Natural Language Processing》的演讲。 Jonathan Mugan专注人工智能、机器学习与自然语言处理的结合。本次演讲中,他重点阐述了如何从自然语言处理到人工智能,以及两条具体路径:符号路线和亚符号路线。
本文基于本次演讲的64页ppt整理汉化完成。点击右上角进入大数据文摘后台,回复“自然语言处理”获取完整版演讲ppt。
人工智能已经变得更聪明。尤其是深度学习,但是,计算机仍不能智能地读取或交谈。 要想了解语言,计算机需要了解世界。他们需要回答类似于下面这样的问题—— 为什么你可以用绳拉马车却不推它? 为什么体操运动员用一条腿竞争是不寻常的? 为什么只有外面下雨? 如果有一本书在桌上,你推桌子,会发生什么? 如果鲍勃去垃圾场,那么他会在机场吗? 让我们以一种基于感觉和行动的方式理解语言——
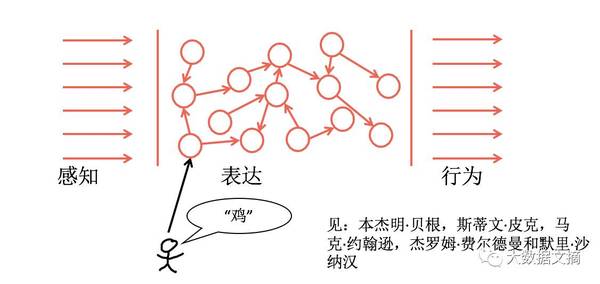
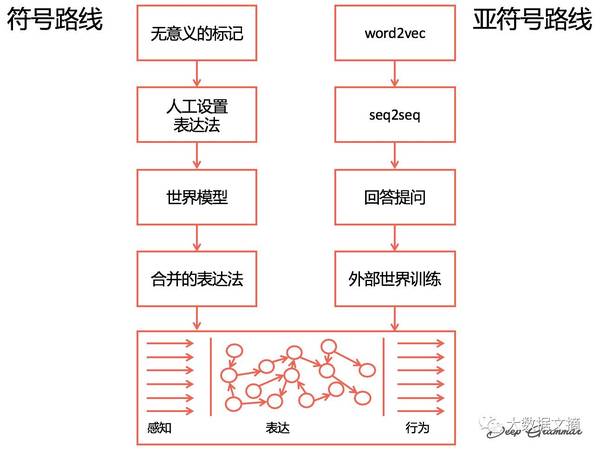
当某人说“鸡”的时候,我们直接把它和我们对于鸡的经验相匹配,我们理解彼此因为我们有相同的经历,这就是电脑需要的一种理解能力。 两种理解含义的路径:
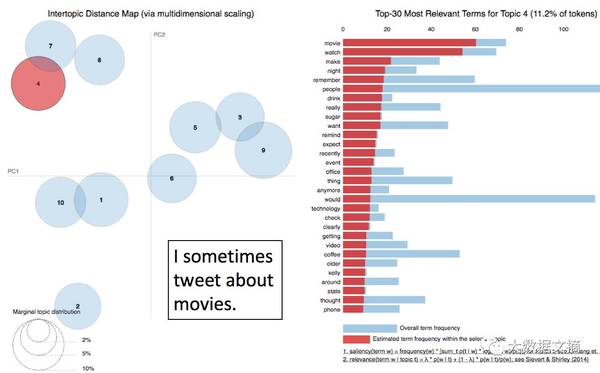
无意义的标记 词袋(Bags-of-words)表述: 将词语视为任意符号,并查看其频率。“狗 咬 人”和“人 咬 狗”完全一致。考虑一个有50,000个单词的词汇表: “aardvark” 的位置是 0 “ate” 的位置是 2 “zoo” 的位置是 49,999 一个词袋可以是一个有50,000维度的向量。 “The aardvark ate the zoo.”= [1,0,1, ..., 0, 1] 我们可以做的更好一点,通过数出这些词数出现的频率。 tf: 词频(term frequency),单词出现的频率。 “The aardvark ate the aardvark by the zoo.” = [2,0,1, ..., 0, 1] 提升非常见词汇: 认为非常见词汇比常见词汇更能表征文本,我们可以得到更好的结果。将每个条目乘以一个表示它在语料库中有多常见的度量。 idf: 逆文本频率指数 idf( 术语, 文本) = log(文本数量 / 包含术语的文本的数量) 10 文本, 只有一个 有 “aardvark” , 5 个有 “zoo” , 5个 有 “ate” tf-idf: tf * idf “The aardvark ate the aardvark by the zoo.” =[4.6,0,0.7, ..., 0, 0.7] 称为向量空间模型。你可以将这些向量放入任何分类器,或者基于类似的向量找到相似的文档。 主题模型 (LDA): 潜在狄利克雷分布(Latent Dirichlet Allocation) 你选择主题的数量 ,每个主题是一个关于单词的分布,每个文档是一个关于主题的分布,在Python主题模型 gensim中很容易操作(https://radimrehurek.com/gensim/models/ldamodel.html ) 通过pyLDAvis在推特上应用LDA:
情感分析:——作者对文本是什么样的感受:
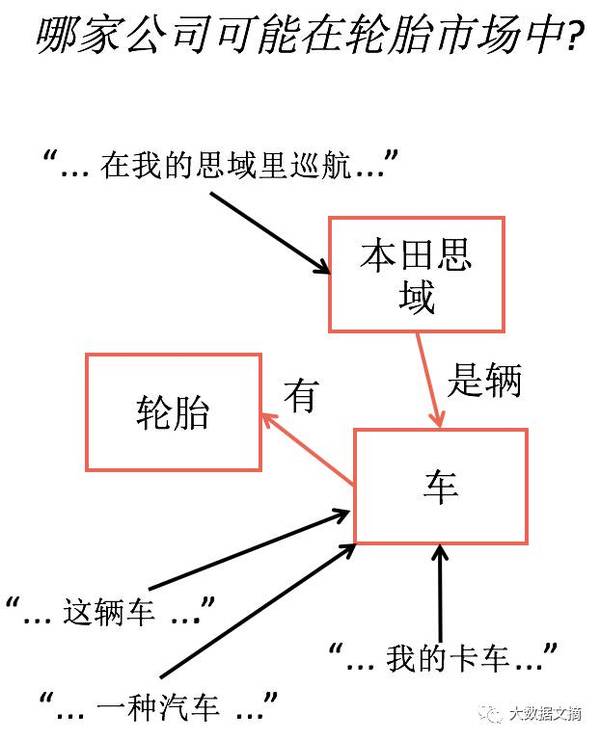
人工设置表达法 我们通过手动指定符号之间的关系来告诉计算机事物的意思。 1.使用预定的关系来储存意思 2.图示多种书写某种同意东西的方法 通过相对较少表述数量,我们可以对机器应该做什么进行编码。
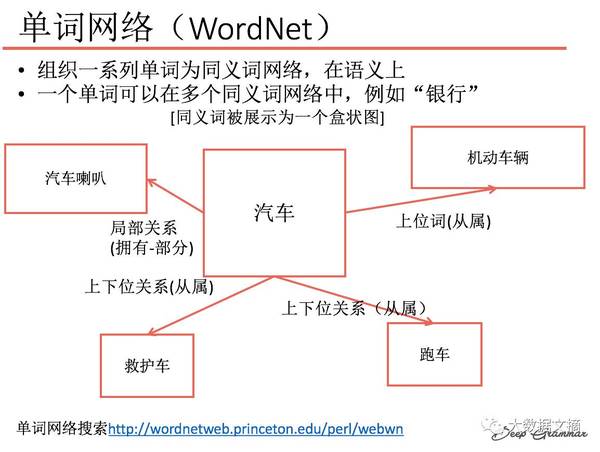
单词网络(WordNet):
框架网络:
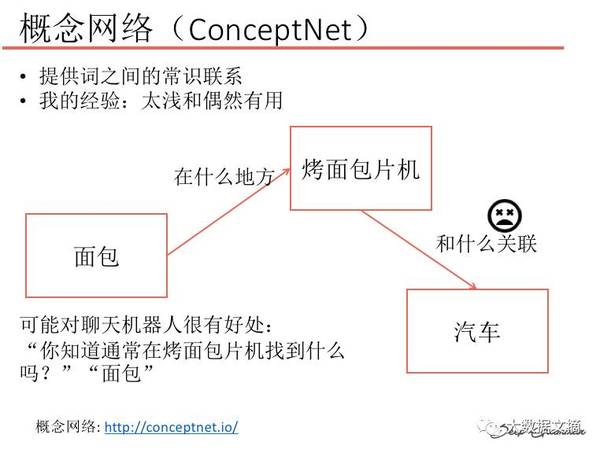
概念网络:
另一个知识本体:
建议上的合并本体:
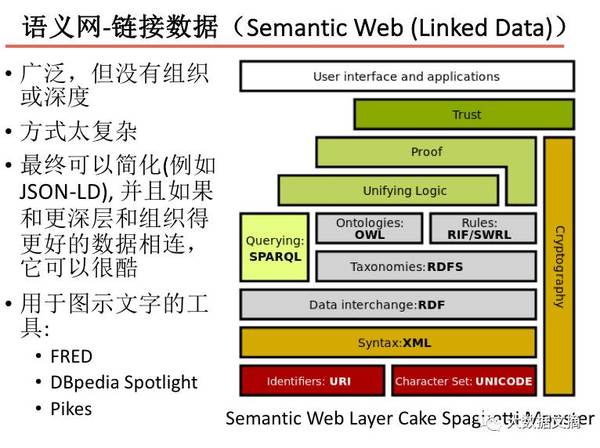
意象图式(Image Schemas): 意象图式是人类关于跨共同文化经验的表示 ——费尔德曼, 2006 人类使用意象图式来理解空间布置和空间运动 ——曼德勒, 2004 意象图式的例子包括路径,先知,阻塞和吸引力 ——约翰逊, 1987 抽象概念例如浪漫关系和论证被表示为这种经验的隐喻 ——莱考夫和约翰逊, 1980 语义网-链接数据:
世界模型 (责任编辑:本港台直播) |