|
编译:弗格森 文强 :COO、执行总编、主编、高级编译、主笔、运营总监、客户经理、咨询总监、行政助理等 9 大岗位全面开放。 简历投递:jobs@aiera.com.cn HR 微信:13552313024 新智元为COO和执行总编提供最高超百万的年薪激励;为骨干员工提供最完整的培训体系、高于业界平均水平的工资和奖金。 加盟新智元,与人工智能业界领袖携手改变世界。 【新智元导读】日前,Facebook AI 实验室负责人、纽约大学教授 Yann LeCun 受邀来到 CMU 进行分享,讲述深度学习领域最近技术进展,并回答听众提问。LeCun 表示,未来几年的挑战是让机器学会从原始的、没有标签的数据中学习,比如从视频或文本中学习,也就是无监督学习。如今的 AI 系统并不具有所谓的“常识”,有些人认为,无监督学习将是机器具有常识的关键。 LeCun认为,对抗式生成网络是近20年来最酷的创造,他个人非常看好。 LeCun 从深度学习的基础讲起,评析了实现无监督学习的几种方法。演讲中,LeCun 结合神经网络历程以及现在为人熟知的各位大牛的相关故事,是一次十分生动而且技术含量丰富的分享。 在新智元微信公众号回复1121,可下载全部PPT。 视频
机器学习历史,从感知机谈起
LeCun:很高兴来到CMU。我第一次到美国来还是30多年前,当时是 Summer School 第一次举办,组织人是 Geoff Hinton 和 Tarry Konarski。 从照片中可以看见年轻的 Geoff Hinton,他当时还是 CMU 的研究员。Tarry Knoafski、Jay McLaren(他当时也在CMU),在 McLaren 旁边是 Michael Jordan。照片上的这些人现在基本都已经成就了一番大事业。还有我,我就在那里(具体位置待补充)。你看,我的头发基本上跟当时一样多呢——这是好事一件。 当时是段美好的时间。那时候是人们第一次开始提起 Backpropagation,Backpro 这个概念在当时真的超级火,虽然论文还没有发表出来——照照片的时候还是 1986 年7月,在章节中涉及 BP 算法的书后来才出版,相关论文也是一年后才在 Nature 发表。 我当时自己也在单独做有关 BP 的一些研究,工作发表后,立即引发了轰动。Hinton 他们也知道了这件事,一年后便去了多伦多(邀请我来美国)……这是我第一次来到美国高校的这样一个环境,体验非常棒。我当时就住在旁边的宿舍,跟一个人合住,他那时候还是法国的大学生,因为我们两个都说法语,j2直播,atv,他们就安排我们两人住一起。现在,他已经成为超级名人,是法国最著名的认识科学家之一,研究意识之类的东西,总之是个很厉害的人。 我现在展示的这张照片显示的是感知机——我们都忘记了 20 世纪 50 年代的感知机,但感知机可以说是所有神经网络的基础。感知机实际上并不是一个计算机程序,而是一台模拟计算机(analog computer) ,这个大家伙的每个模块(module)都是一个权重。与神经元模型不同,感知器中的权值是通过训练得到的。你只要一按键,当系统发生错误时,所有的模块都会“死过去”。 感知机运行权重实际上取决于你按键的时间有多长。那块平板就是特征提取器。现在用 Python 很轻松就能实现,但在当时这可是一件难事。感知器类似一个逻辑回归模型,可以做线性分类任务。由此产生出了特征提取模型以及后来的分类模型,几十年来一直被作为物体识别的标准方法被人使用。 我们都知道监督学习是什么了,而我之所以要提监督学习,是因为后面我们会涉及为什么它有局限。在机器学习中,我们将样本——比如汽车或者飞机的图像,输入有很多可调参数的机器里——这实际上是一个类比。当输入的是一辆车时,红灯就会亮,当输入是飞机时就打开绿灯。然后我们就不停调整参数。通过增加梯度,我们可以调整亮绿灯的次数。 深度学习原理和典型应用介绍
深度学习:整个机器都是可训练的 传统模式识别、现代主流的模式识别与深度学习的区别:代表(Representations)是分层的并且可训练的。
监督学习:机器可以识别自己从未见过的东西吗?
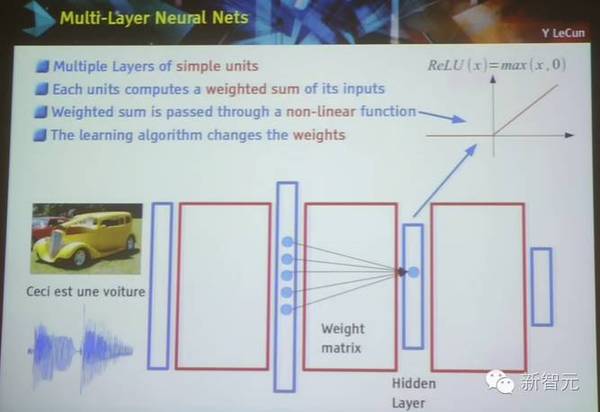
多层神经网络: 一个单元包含多层神经网络 一个单元计算其获得的输入的一部分加权和 加权和会通过一个非线性函数 学习算法会改变权重
反向传播的梯度计算
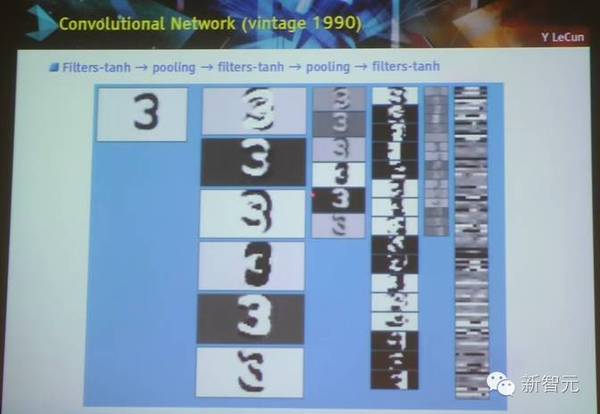
卷积网络架构
卷积网络工作流程的可视化
用于物体识别的深度卷积网络
深度学习就是学习各层中的表征
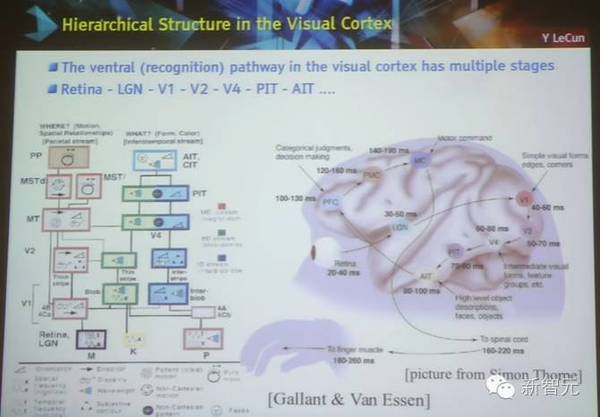
视觉皮质层上的层级结构
极深的卷积网网络架构:VGG、 GoogleNet、ResNet
监督式的卷积网络
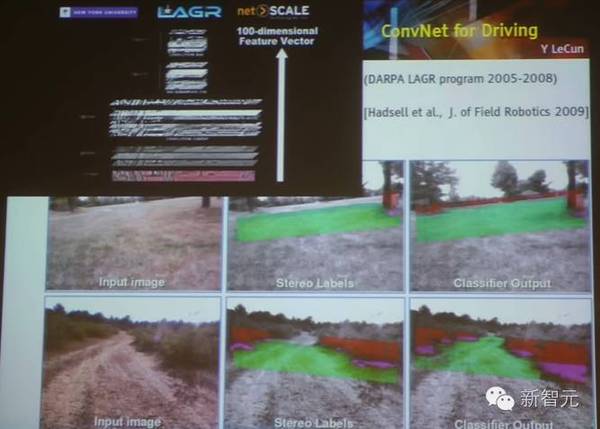
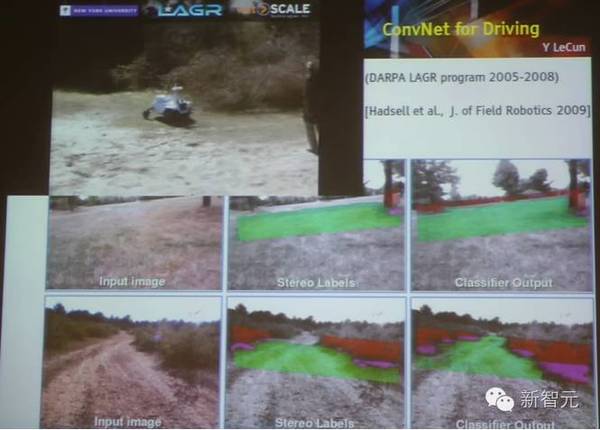
用于自动驾驶
用于机器人
使用卷积网络生产图说、词义分割
使用卷积网络进行的自动驾驶
DeepMask:卷积定位和物体识别
几个图像识别的案例 记忆增强网络(差分计算)
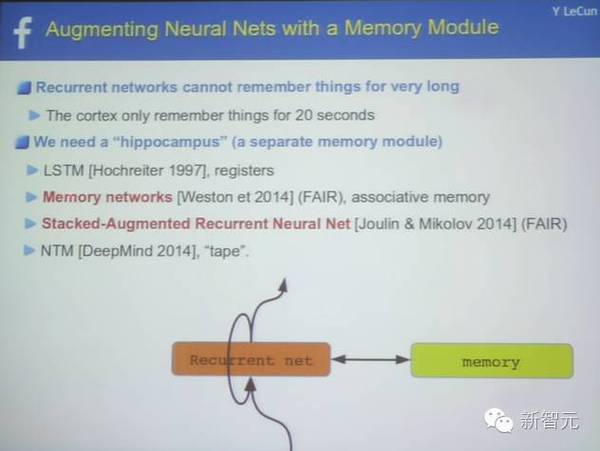
用一个记忆模块增强神经网络 递归神经网络不能长久地记忆 需要一个额外的记忆模块
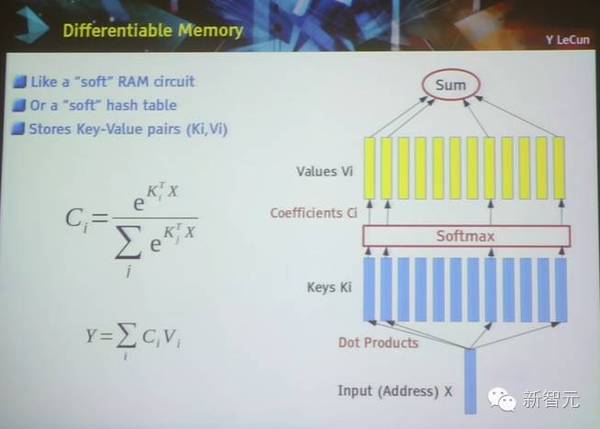
差分记忆
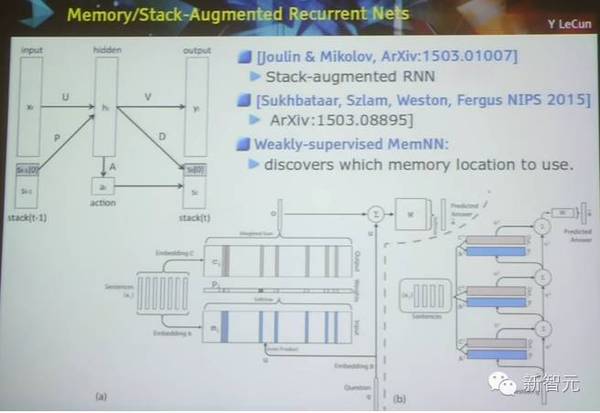
记忆/堆栈 增强递归网络
记忆网络研究 使用案例:问答系统
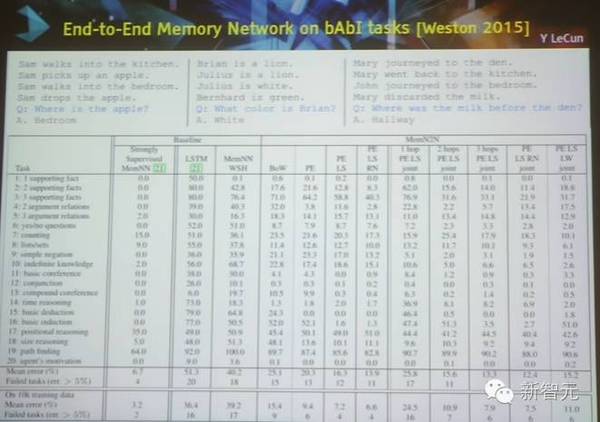
bAbI任务中,端到端的记忆网络
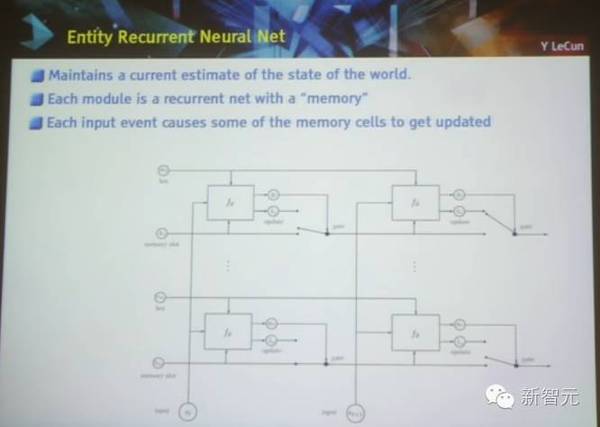
实体递归神经网络
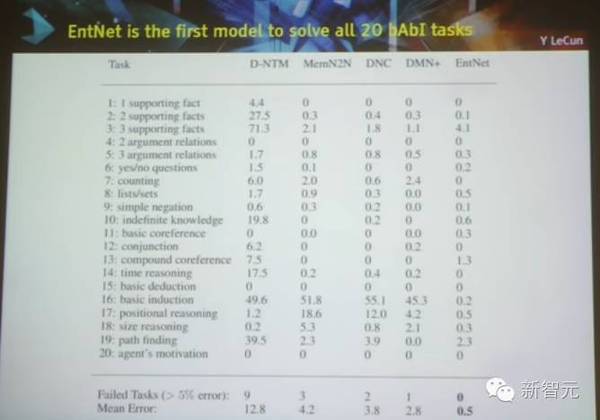
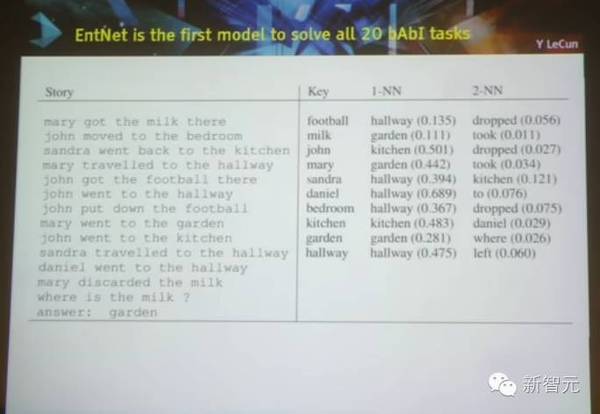
EntNet 是世界上首个解决了所有20个bAbI任务的模型 AI 面临的阻碍:常识
1. 机器需要学习/理解世界的运转方式 物理世界、数字世界、人 需要掌握常识 2. 机器需要学会大量的背景知识 通过观察或者行动 3.机器需要感知世界的变化 以作出精准的预测和计划 4.机器需要更新并记住对世界状态的预测 关注重大事件、记住相关事件 5. 机器需要会推理和计划 预测哪些行动会带来预期的改变 智能&常识=感知+预测模型+记忆+推理&计划
什么是常识?代词“它”的指代对象,动作的执行者。机器该怎么理解。
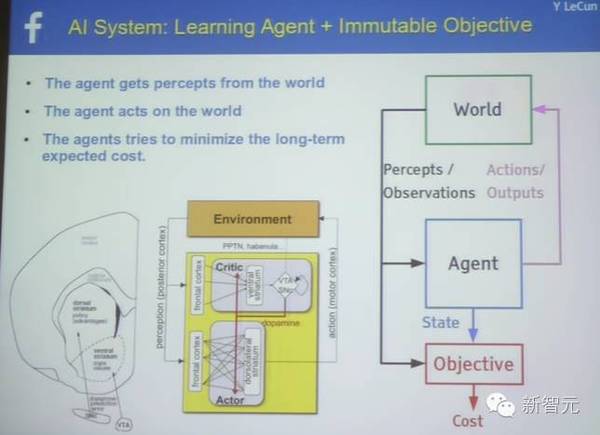
增强学习、监督学习、非监督学习在预测上的不同 智能系统的架构:学习智能体+不可变对象
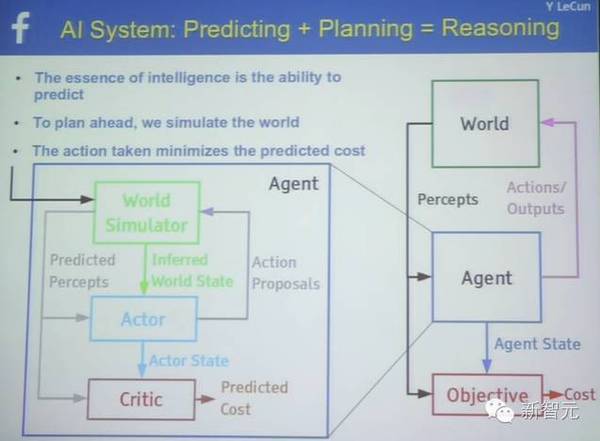
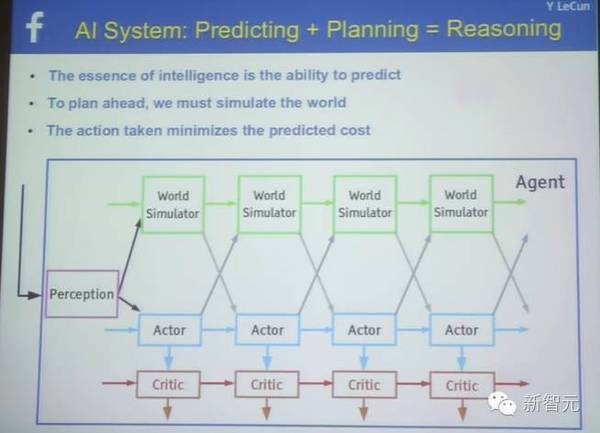
AI 系统详解:预测+计划=推理
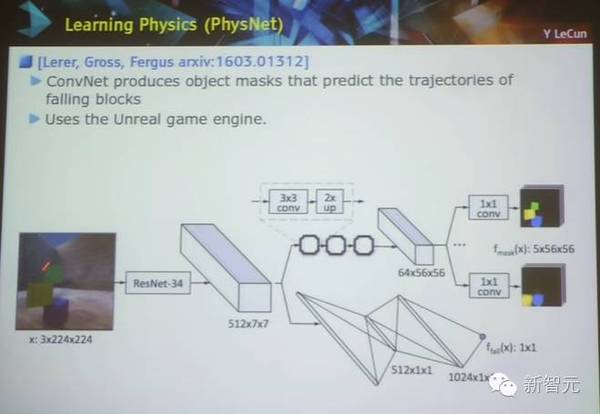
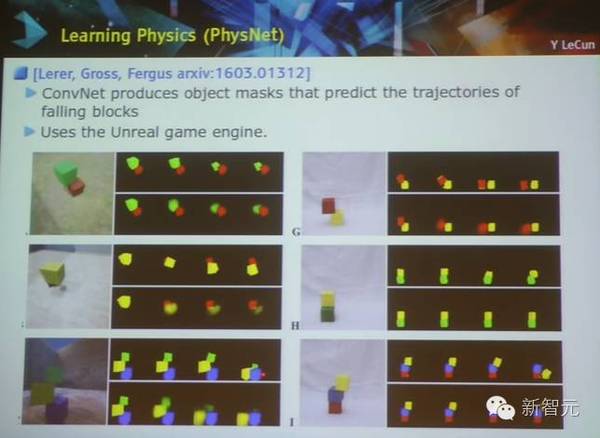
学习物理:物理网络
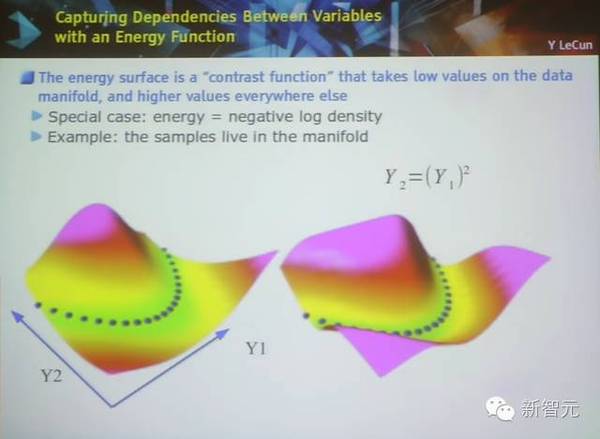
非监督学习:能量函数
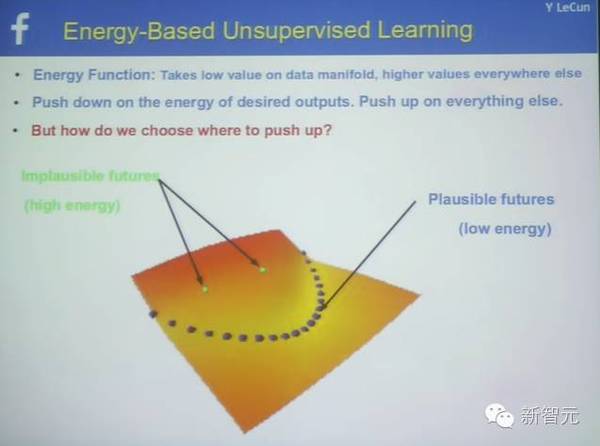
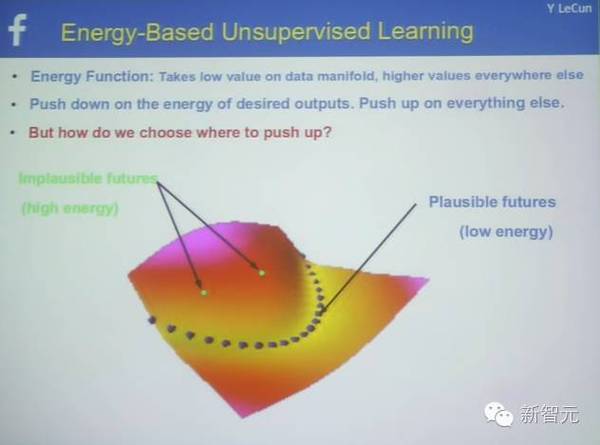
基于能量的非监督学习,能量函数
塑造能量函数的7大步骤
对抗训练,20年来最酷的技术
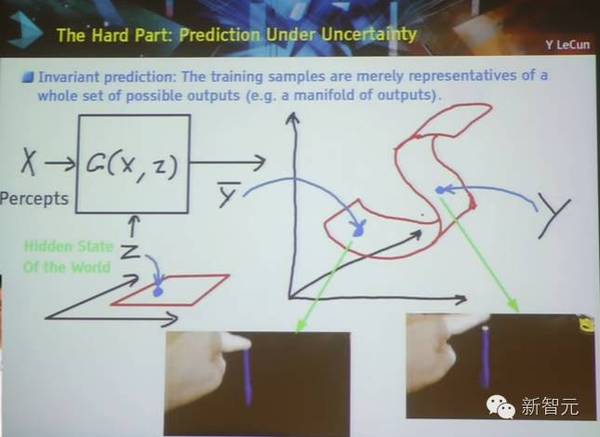
难点:在非确定性的情况下做预测
基于能量的非监督学习
对抗训练:可训练的对象函数
在图像识别上的应用
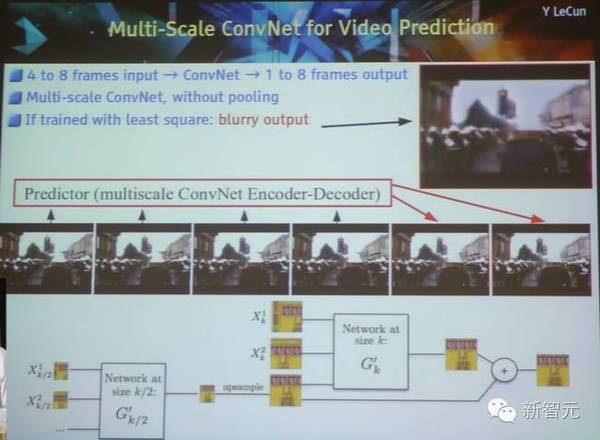
对抗训练实例:视频预测
|