|
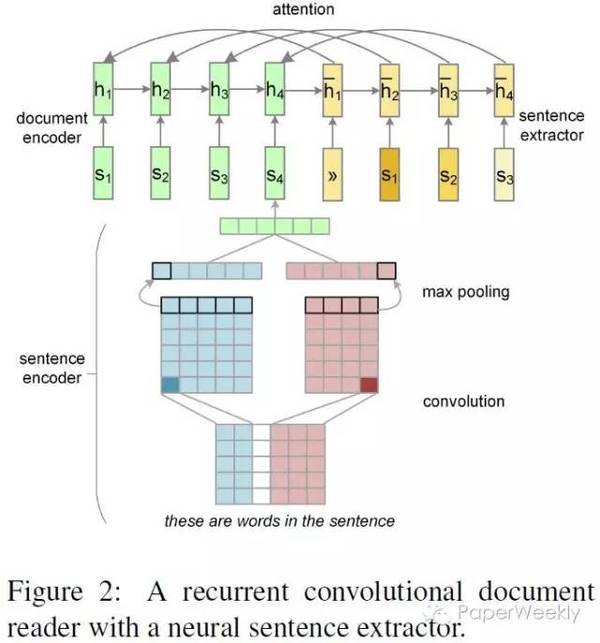
该工作为在第一篇文章基础上的改进工作,做了大量的实验,非常扎实。文章提出的feature-rich encoder对其他工作也有参考意义,即将传统方法中的特征显式地作为神经网络的输入,提高了效果。 3、Neural Summarization by Extracting Sentences and Words作者 Cheng, Jianpeng, and Mirella Lapata. 单位 University of Edinburgh 关键词 Extractive Summarization, Neural Attention 文章来源 ACL 2016 问题 使用神经网络进行抽取式摘要,分别为句子抽取和单词抽取。 模型
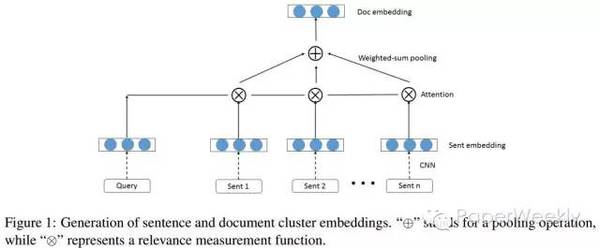
句子抽取 由于该工作为文档的摘要,故其使用了两层encoder,分别为: 词级别的encoder,基于CNN。即对句子做卷积再做max pooling从而获得句子的表示。 句子级别的encoder,基于RNN。将句子的表示作为输入,即获得文档的表示。 由于是抽取式摘要,其使用了一个RNN decoder,但其作用并非生成,而是用作sequence labeling,对输入的句子判断是否进行抽取,类似于pointer network。 词的抽取 对于词的抽取,该模型同样适用了hierarchical attention。与句子抽取不同,词的抽取更类似于生成,只是将输入文档的单词作为decoder的词表。 数据 从DailyMail news中根据其highlight构建抽取式摘要数据集。 简评 该工作的特别之处在于对attention机制的使用。该paper之前的许多工作中的attention机制都与Bahdanau的工作相同,即用attention对某些向量求weighted sum。而该工作则直接使用attention的分数进行对文档中句子进行选择,实际上与pointer networks意思相近。 4、AttSum: Joint Learning of Focusing and Summarization with Neural Attention作者 Cao, Ziqiang, et al. 单位 The Hong Kong Polytechnic University, Peking University, Microsoft Research 关键词 Query-focused Summarization 文章来源 COLING 2016 问题 Query-focused多文档抽取式摘要 模型
由于该任务为针对某个query抽取出可以回答该query的摘要,模型使用了attention机制对句子进行加权,加权的依据为文档句子对query的相关性(基于attention),从而对句子ranking,进而抽取出摘要。具体地: 使用CNN对句子进行encoding 利用query,对句子表示进行weighted sum pooling。 使用cosine similarity对句子排序。 数据DUC 2005 ? 2007 query-focused summarization benchmark datasets 简评 该文章的亮点之处在于使用attention机制对文档中句子进行weighted-sum pooling,以此完成query-focused的句子表示和ranking。 总结 本次主要介绍了四篇文本摘要的工作,前两篇为生成式(abstractive)摘要,后两篇为抽取式(extractive)摘要。对于生成式摘要,目前主要是基于encoder-decoder模式的生成,但这种方法受限于语料的获得,而Rush等提出了利用English Gigaword(即新闻数据)构建平行句对语料库的方法。IBM在Facebook工作启发下,直接使用了seq2seq with attention模型进行摘要的生成,j2直播,获得了更好的效果。对于抽取式摘要,神经网络模型的作用多用来学习句子表示进而用于后续的句子ranking。 广告时间 PaperWeekly是一个分享知识和交流学问的学术组织,关注的领域是NLP的各个方向。如果你也经常读paper,也喜欢分享知识,也喜欢和大家一起讨论和学习的话,请速速来加入我们吧。 微信公众号:PaperWeekly 微博账号:PaperWeekly() 微信交流群:微信+ zhangjun168305(请备注:加群 or 加入paperweekly) (责任编辑:本港台直播) |