|
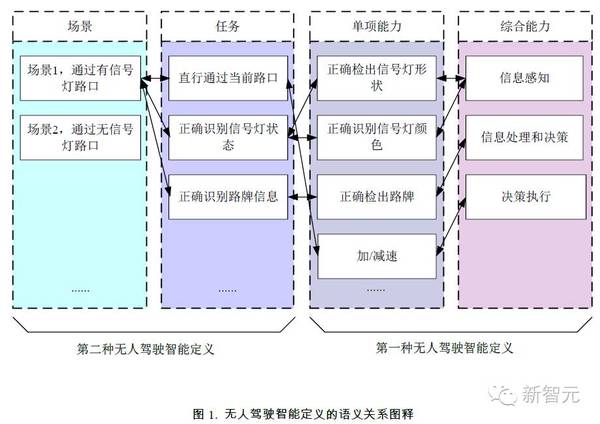
作为一个具体的人工智能造物,无人驾驶车辆也是通过测试的方法来定义的。实际上,Dr. Little 在 1997 年提出 Intelligent Vehicle Initiative 这一概念时就指出, 能够完成避撞、停车等多项具体任务的汽车即可被视为智能汽车。不难看出,这 一“定义”本身就是通过“测试”实现的。 早在几年前,美国高速公路安全管理局(NHTSA)与美国汽车工程师学会(SAE) 等机构便相继公布了无人驾驶的自主能力等级分级。以 SAE 分级为例,前三级 以人为主:0 级为完全手动驾驶,1 级是软件辅助人员驾驶,2 级为局部模块自 动化;后三级便是以“车”为主了,3 级可以在某些环境下达到自动驾驶,4 级的 时候车辆能做到基本在自主驾驶,最后,5 级是完全自主驾驶,也是最令人憧憬 的完全无人化运行。一般情况下,前三级(0-2)是驾驶员在观测、感知、判断驾驶 环境,后三级(3-5)就是自主驾驶系统在做这部分工作了。 然而,上述定义依然较为抽象和模糊。无人驾驶测试的新问题变成了“如何 能保证一辆无人驾驶车辆能够在真实交通环境中安全而顺畅的行驶?” 2. 传统的无人驾驶车辆智能测试 传统的无人驾驶车辆智能测试主要分为两大流派:场景测试流派和功能测试流派。 场景测试往往是指处在特定时空中的测试系统。例如,交通场景一般指的是由众多交通参与者和特定道路环境共同构成的交通系统。如果受试车辆能够自主行驶通过该交通系统,则称为通过该特定场景的驾驶测试。例如DARPA 2005 年 无人车挑战赛便选取了 212 公里的沙漠道路作为测试场景(其实 2004 年也是选 择了沙漠作为测试场景,但是“全军覆没”,相比之下,2005 年则是一段光辉岁 月)(Grand Challenge 2005)。DARPA 2007 年无人车挑战赛则选取了 96 公里的城 市道路作为测试场景(Urban Challenge 2007)。 场景测试的隐含假设是,如果无人驾驶通过某种场景的一次或几次测试,那 么,以后遇到该场景也可以顺利通过。但这一假设未必总是成立(理想很丰满,但现实往往很骨感。即使是人类驾驶员,在通过驾照考试后,也会在实际交通环 境中出现失误)。此外,目前的场景测试还存在许多问题,例如: a) 无法对车辆系统的认知、决策和行为进行详细的记录和分析,难以进行定量评估。对于人类驾驶者而言,感知、决策、执行三者共同作用,产生智能驾驶行为。而传统的场景测试只关注驾驶的最终效果。当如果驾驶效果不好时,难以 确定是感知不正确,还是决策不智能,亦或执行不到位等,对于改进车辆智能水 平的指导性不足。 b) 真实交通场景复杂多变,测试场景无法遍历所有情况,甚至难以做到对典型场景的全覆盖。 c) 测试难度不易控制,无法做到增量式提升。 d) 具体测试难以重复,耗时多,费用高。 功能测试则更加侧重无人驾驶的单项或多项功能实现。依据人类智能的功能归类方式,可将驾驶智能划分成信息感知、分析决策、动作执行等较为概括的三 大类能力。例如路径规划就属于分析决策类的单项智能。该定义方式强调的是实现这些单项智能的方法和技术上的共性。但由于不能与具体的交通场景以及无人 驾驶测试任务联系起来,在衡量无人驾驶的智能水平方面有所不足。 功能测试的隐含假设是,如果无人驾驶通过某种功能的一次或几次测试,那 么,以后需要使用该功能时也可以顺利执行。这一假设看似合乎逻辑,但事实证明,也过于乐观。 此外,目前的功能测试还存在其它问题: a) 单一功能测试较多,综合测试涉及较少,无法检验多项功能之间的协同配合能力。 b) 缺少完备、公平、公开的 Benchmark 集。 3. 无人驾驶车辆智能的语义网络定义 我们认为,无人驾驶车辆的智能可以用广义的语义网络来定义。 语义网络最早由奎廉于 1968 年提出,是一种采用网络形式表示人类知识的方法,如今已在人工智能领域中得到了比较广泛的应用。语义网络用有向图来表 达复杂的概念及其之间的相互关系。图中的顶点表示概念,而边则表示这些概念间的语义关系。 针对无人驾驶智能的广义语义网络分为场景、任务、单项能力和综合能力四 类节点。其中任务将场景和能力打通并连接起来,应该是无人驾驶智能研究的核心,参见图1。
|