|
近日,台湾清华大学电子工程系教授林嘉文及孙敏宣布,他们与微软亚洲研究院的陶玫博士合作研发利用计算机视觉技术为视频内容添加标签和标题。
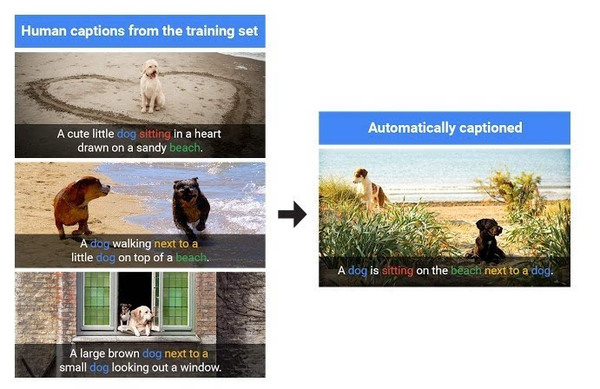
据悉,陶玫博士曾参与了微软 COCO 的研发。微软 COCO 是一套全新的图像识别、分类、说明的数据集,为识别多个物体设计而出。被业内熟知的是微软 COCO 图像说明大赛,参赛者利用自主研发的图像识别系统并结合微软 COCO 对指定图像进行文字说明。结果则根据系统说明的准确率、详细程度以及跟人类描述的相似度进行评估。 微软表示, 台湾清华大学两名教授借助微软 COCO 数据集创建了一套系统, 利用计算机视觉技术来确定视频里的主要内容,并为其添加标题。 微软在博文中指出: 孙教授基于深度学习来自动找到视频中的特殊时刻或重要内容,并创建了一个视频标题生成新方法,基于视频中的这些重要内容产生准确及有趣的标题。与此同时,林教授则研发了一种能自动在视频中检测人脸的方法,并为分享这些视频的用户提供更丰富的总结及相关建议。 通过合作,他们的算法能检测并描述出重要内容,同时生成标签及标题。 孙敏教授和他的学生还通过参加 VideoToText challenge 大赛来改善这一系统。消息称,他们将在欧洲计算机视觉会议(ECCV)上展示最新研究成果。 解释和描述视频/图片画面中的内容,不仅需要了解图片中是什么,更要了解图像中的对象有什么联系。利用算法识别视频内容然后生产标题或者标签相对来说难度和计算量更为庞大,而识别图片内容从而生成标签或画面描述文字已愈加成熟。 上个月谷歌发布了最新机器学习系统,通过识别图像中的内容,配上对应文字,目前算法描述图像的准确率已经高达 93.9%。
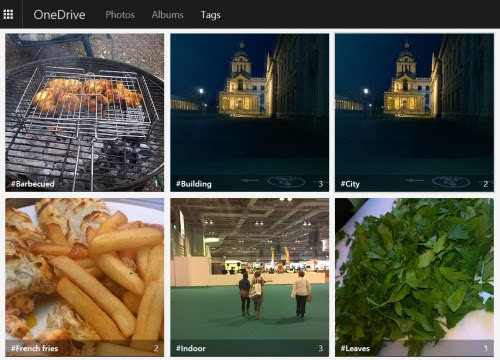
得益于 COCO,微软在图片描述上也有着一定的积累,其中被广泛应用地就是 One Drive 中的相册归类功能。该功能可以让用户有效分类并展示照片,还能从图片中识别文字。当然,最重要的是它还能对图片特征进行识别分析并进行自动标记。
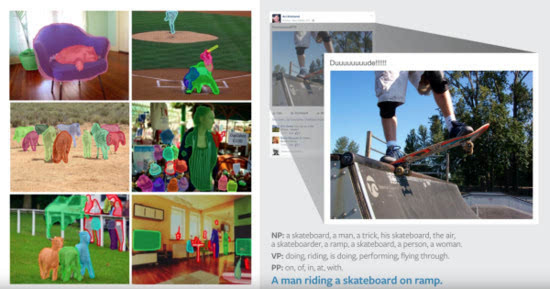
除了微软、谷歌外,Facebook 也在今年发布了类似的系统,该系统可以了解照片中正在发生的事情,并且将内容转换成自然语言来描述。Facebook 演示了一个人玩滑板的照片。算法把照片内容分解成“一个滑板,开奖,一个男人,一个绝招,他的滑板”,它认为可能已经发生的事情是“做的,玩滑板,atv直播,正在做”。用户可借助 VPN 翻墙到 iPhone 版 Facebook 后使用,同时也能利用 iPhone 自带的 voiceover 功能对于本来有文字描述的东西都能读出来。
无论是图片描述还是视频描述,在消费级层面:其不仅可帮助用户自动管理相册(视频集)。此外,该技术可以帮助盲人用户用语音解读照片和视频中的内容。 (责任编辑:本港台直播) |