|
2016年8月,一位自称“Peace”的黑客声称盗取了2亿雅虎用户账户和密码,并寻求在暗网(dark web)上进行售卖。黑客所声称的2亿条信息的泄露似乎盗取自2012年,同时发生的还有MySpace(3.6亿条)和Linkedln(1亿条)两家网站的信息泄露。 有趣的是 Linkedln 的泄露事件还间接导致了扎克伯格的推特账号被黑。因为扎克伯格在两个网站都使用了同一个密码:“dadada”…… 在信息化时代,数据泄露无处不在,这种风险可能来自于我们上网的每一个步骤。下面笔者将介绍一种批量获取信息的方式——爬虫。编程语言基于Python,如果对这门语言不是很熟悉可以先了解下它的语法结构。本文将对于爬虫做一个简单入门介绍。 关于爬虫 我们一直在说的爬虫究竟是个什么鬼? 网络爬虫(web crawler),是一个自动提取网页的程序,它为搜索引擎从网路上下载网页。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索。 (摘自百度百科) 简单来讲,爬虫是通过程序或者脚本获取网页上的一些文本、图片、音频的数据。 从笔者的经验来看,做一个简单的爬虫程序有以下几个步骤:确立需求、网页下载、网页分析与解析、保存。接下来大家可以跟随笔者的流程,直播,我们来写个抓取豆瓣书籍信息的爬虫。 1、 需求 以豆瓣读书为例,我们爬取豆瓣的书籍信息,需要获取的信息包括:图书名称,出版社,作者,年份,评分。
2、 网页下载 页面下载分为静态和动态两种下载方式。 静态主要是纯 html 页面,动态是网页会使用 java 处理,并通过Ajax 异步获取的页面。在这里,我们下载的是静态页面。 在下载网页的过程中我们需要用到网络库。在 Python 中有自带的 urllib、urllib2 网络库,但是我们一般采用基于 urllib3 的第三方库Requests ,这是一个深受 Pythoner 喜爱的更为高效简洁的网络库,能满足我们目前的 web 需求。 3、 网页分析与解析1)网页分析: 选好网络库后我们需要做的是:分析我们要爬取的路径——也就是逻辑。 这个过程中我们要找到爬取的每一个入口,例如豆瓣读书的页面。已知图书标签的 url,点击每个 url 能得到图书列表,在图书列表中存放需要的图书信息,求解如何获得图书信息。 所以很简单!我们的爬取路径就是:图书标签 url —> 图书列表—>图书信息。 2)网页解析: 网页解析主要就是通过解析网页源代码获取我们需要的数据,网页解析的方式有很多种,如:正则表达式, BeautifulSoup, XPath 等等,在这里我们采用的是 XPath。Xpath 的语法很简单,是根据路径来进行定位。
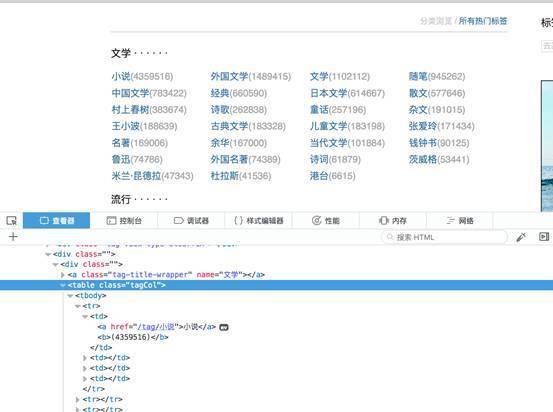
举个栗子:上海的位置是 地球—中国—上海,语法表达为 //地球/中国[@城市名=上海] 接下来我们需要解析网页获取到图书的 tag 标签的url。打开网页,右击选择审查元素,然后就会出现调试工具,左上角点击获取我们需要的数据,下面的调试窗口就会直接定位到其所在代码。
根据其位置,写出其 Xpath 解析式://table[@class='tagCol']//a 这里我们看到小说在一个< table >标签下的< td >标签的< a >标签里。< table > 标签可以用 class 属性进行定位。
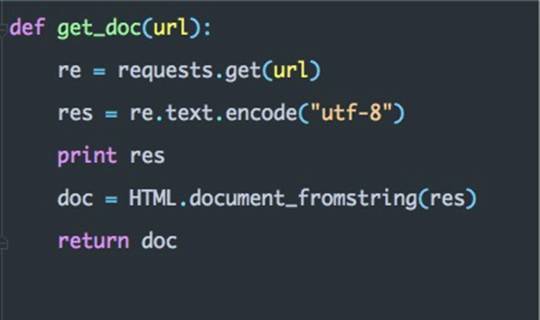
以下是获取 tag 的 url 的代码:
获取完了 tag ,我们还需要获取到图书的信息,下面我们对图书列表页进行解析:
解析之后代码如下:
爬取的信息内容如下:
4、 数据保存 (责任编辑:本港台直播) |