|
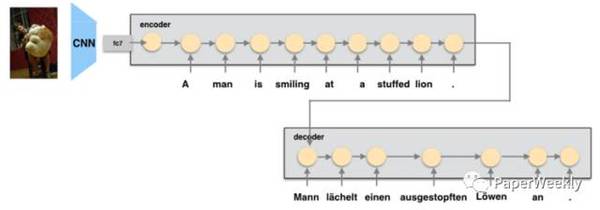
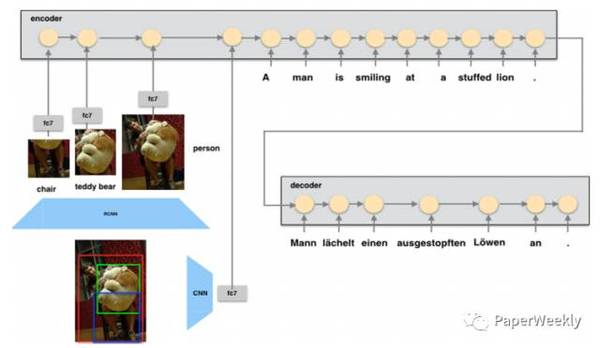
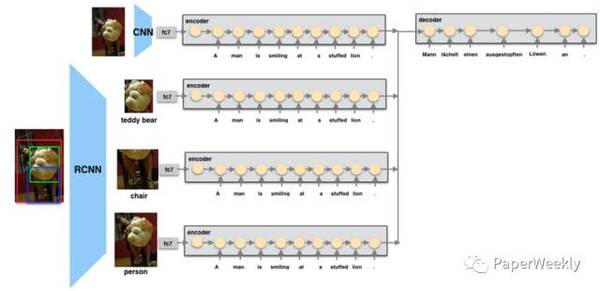
多信息融合是一个重要的研究趋势,尤其是对于训练数据缺乏的任务来说,如何融入其他相关信息来提高本任务的准确率是一个非常值得研究的问题。机器翻译是一个热门的研究领域,随着训练数据规模地增加,各种NN模型的效果也取得了突破的进展,google和百度均已部署上线NMT系统;融合图像、音频、视频、文本等各种模态数据的多模态研究也是一个非常热门的研究方向,本期PaperWeekly将为大家带来NMT和多模态交叉研究的paper解读,共3篇paper: 1、Attention-based Multimodal Neural Machine Translation, 2016 2、Multimodal Attention for Neural Machine Translation, 2016 3、Zero-resource Machine Translation by Multimodal Encoder-decoder Network with Multimedia Pivot, 2016 Attention-based Multimodal Neural Machine Translation作者 Po-Yao Huang, Frederick Liu, Sz-Rung Shiang, Jean Oh, Chris Dyer 单位 CMU 关键词 Visual Features, Attention, Multimodal NMT 文章来源 ACL 2016 问题 多模态神经机器翻译,在传统的seq2seq翻译模型上,利用图像特征信息帮助提高机器翻译的结果 模型 在WMT16的多模态神经网络机器翻译新任务上的工作。 提出了3种如何将visual feature加入到seq2seq网络中的encoder,从而使得decoder更好的attention到与图像,语义相关部分的模型: global visual feature, regional visual feature,paralle threads.
global visual: 直接将VGG中的fc7抽出的feature加入到encoder的first step(head)或者是last step(tail)
regional visual: 先用R-CNN抽出region box的信息,再用VGG得到fc7的特征,将top4对应的region feature,以及global visual feature分别作为每一个step输入到encoder中
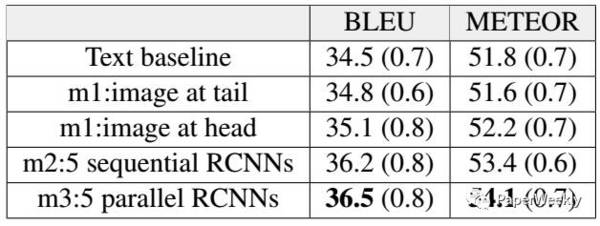
parallel threads: 与regional visual相对应的是,每个thread只利用一个region box的feature,和global visual一样的网络,将top 4对应的4 threads和gloabl thread一起做average pooling,每个therad的参数共享; attention则对应所有threads中的所有hidden states 同时本文还提出了三种rescoring translation的结果的方法, 用 1)language model 2)bilingual autoencoder 3)bilingual dictionary分别来挑选translation的句子,发现bilingual dictionary来删选翻译的句子效果最好 资源 数据集: WMT2016 (En-Ge) 图像特征提取: VGG, R-CNN 实验结果 在En-Ge的结果如图:
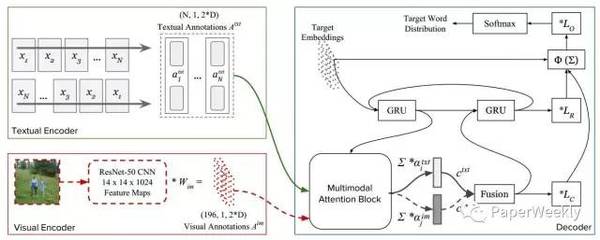
相关工作 NMT: Kalchbrenner and Blunsom 2013 Attention NMT: Bahdanau 2014 Joint Space Learning: Zhang 2014,Su 2015,Kiros 2014 多模态上相关工作目前并没有很多,值得快速入手 简评 本文提出了一种针对图像和文本结合的神经网络翻译模型,非常自然的将图像特征加入到seq2seq模型的encoder部分,使decoder不仅能够attention在文本上,同时也能够focus到图像上(global或者region);并且模型的设计比较简单,没有加入太多复杂的模块。 不过只是简单的将图像的特征作为seq中的一个step,并没有考虑文本和图像之间的相关关系,如joint space,相信加入joint learing会有提升。 完成人信息 Lijun Wu from SYSU. Multimodal Attention for Neural Machine Translation作者 Ozan Caglayan, Loïc Barrault, Fethi Bougares 单位 University of Le Mans, Galatasaray University 关键词 NMT, Attention 文章来源 arXiv 2016.09 问题 给定图片和源语言描述的情况下,基于attention机制,生成目标语言的图片描述。 模型 模型有两个encoder,一个是textual encoder,是一个双向GRU,用于获取源语言文本的向量表示$A^{txt} = {a^{txt}_1,a^{txt}_2,…}$,另外一个是visual encoder,使用的是现成由ImageNet数据集训好的ResNet-50网络,用于获取图片的向量表示。$A^{im} = {a^{im}_1,a^{im}_2,…}$. Decoder部分,是两层的stakced GRU,先用attention方式,分别获取文本部分和图像部分的context向量$c^{txt}$和$c^{im}$,然后将两个向量concat在一起,作为新的context 向量$c$。 如图:
这样decoder部分的解码翻译的时候,不仅可以考虑到源语言的文本信息,也可以考虑到原始图片的信息。 资源 IAPRTC-12 dataset for English and German 相关工作 (责任编辑:本港台直播) |