|
雷锋网按:曲晓峰,香港理工大学人体生物特征识别研究中心博士生。雷锋网(搜索“雷锋网”公众号关注)独家文章,转载请联系授权。 近期,两个我曾使用过的云计算平台 Sense.io 和 getdatajoy.com,即将逝去。前者被收购,已经对个人用户关闭;后者即将在 2017 年 1 月 2 日关站。 在人工智能爆发的今天,两个本应是智能计算核心的云计算平台,不仅没有乘风而起、顺势化龙,却倒在了新时代的门槛上,不得不引起人深思。 |Sense.io —— 按需分配计算能力
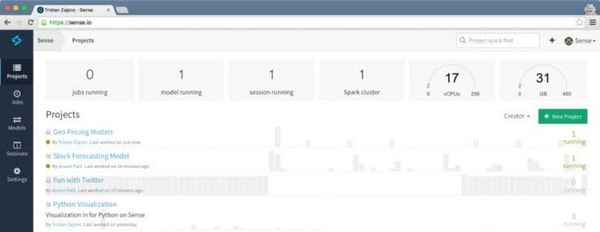
在 Sense.io 上,各个项目可以使用不同运算能力的平台,分别运行。单个项目可以使用多个虚拟 CPU 和或大或小的内存空间。 Sense.io 是一个面向数据科学家的可以动态分配计算能力云计算平台,简单说来就是“数据科学家的 GitHub”。在 Sense 上,数据科学家可以与其他人协作,并生成数据报表。 2016 年 3 月 22 日,Sense 宣布被大数据软件公司 Cloudera 收购。Sense 的创始人 Tristan Zajonc 和 Anand Patil 在 Sense 的博客上发布了被收购的公告,同时宣布免费和个人服务 2016 年 4 月 31 日关闭。 在 Sense 上,用户可以直接用 Python、R、Julia 编写代码,进行算法实验,构建模型,然后根据算法需要和成本综合考虑,选择具有合适运算能力的云计算平台(虚拟 CPU、内存)运行,然后输出、保存结果。运行的程序,可以是一次性的函数,也可以使用一种类似 Jupyter 的交互式执行环境来单步执行,分别看输出的结果。输出的结果可以是数据文件,如 CSV,可以是 png、jpg 等格式的图片,又或者可以用 java 动态图表展示出来。最后也可以生成 markdown、pdf 的报告。 我曾经用 Sense.io 进行过一些数据分析。 其最大的优点就是运算能力可配置的特性。在进行实验的初期,使用稍小的运算能力,用单 CPU 检查数据,调试算法,检验假设。当实验流程比较清晰明确,代码跑通之后,就可以换用大运算能力,用 16、32、64 核和大内存载入所有数据进行运算,尽快获得实验结果。尤其是同一方向的实验,可以简单地通过复制项目,修改参数、添加函数或者调整流程,迅速并行展开多种实验。数据可以上传到同机房的 AWS 数据服务器,如:S3、DynamoDB、或者 Redshift,以方便不同项目共享访问或者同一项目的多次快速存取(sense.io 是搭建在 AWS 基础设施之上的)。 其实,做科研或者做商业数据分析都会遇到这样的问题,atv,在构思算法或实验初期,并不总是在编程和运算,检查、清洗数据与思考占用前期大量时间。 直到有了比较清晰的方向,需要用数据和结果来验证想法的时候,才需要大量甚至是海量的运算。当然,两种情况是经常是交替进行的,一段时间慢慢思考调试;一段时间跑大量的数据来看整体的输出。在进行批量运算的时候,甚至会去抢别人的电脑来跑实验。使用 Sense.io 这种方案,可以有效充分地利用运算能力。一方面不至于在概念验证的初期就浪费大量的运算能力;另一方面,在需要的时候,可以迅速拓展克隆,在短时间内调动大量的运算能力迅速得到结果。 与现有的其他网站相比,Sense.io 更为灵活与已用。其预先配置好了编程环境,包括 Python、R 和 Julia 等数据分析最为常用的开源语言的开发环境,可以直接上手工作。不需要配置虚拟机、配置虚拟网络、安装系统、安装软件环境等一整套繁复的环境配置工作。 同时,协作与共享也变得相当简单。直接登陆在线帐户,进入同一个工程项目,就可以进行协作。或者直接克隆一个当前工作的镜像工程交给他人接手开发。 从服务器运营角度上看,这也是比较合理的方案。每个用户的使用峰值不同,不同用户错峰使用更能提高服务器的利用率。甚至,可以通过调整峰谷运算能力的价格,j2直播,来进一步的平谷抑峰。 但可惜,被 Cloudera 收购后,Sense 已经对个人用户关闭,不知道 Cloudera 未来会不会开放 Sense 动态调整运算能力的技术。 | DataJoy —— 学术文档与代码的融合
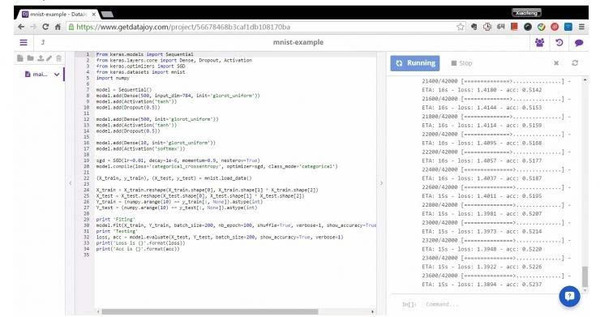
在 DataJoy 上运行基于 Keras 的全连接深度网络学习识别 MNIST 手写字符的例子。 (责任编辑:本港台直播) |