|
接下来我介绍新版AlphaGo,也被称为AlphaGo Master,这次对战柯洁的新版AlphaGo。AlphaGo Mater使用更加有效的算法,所需的计算量是AlphaGo的1/10。这张图显示了AlphaGo Mater使用的硬件,通过谷歌云提供的一块TPU,你可以把它当做是一台计算机。
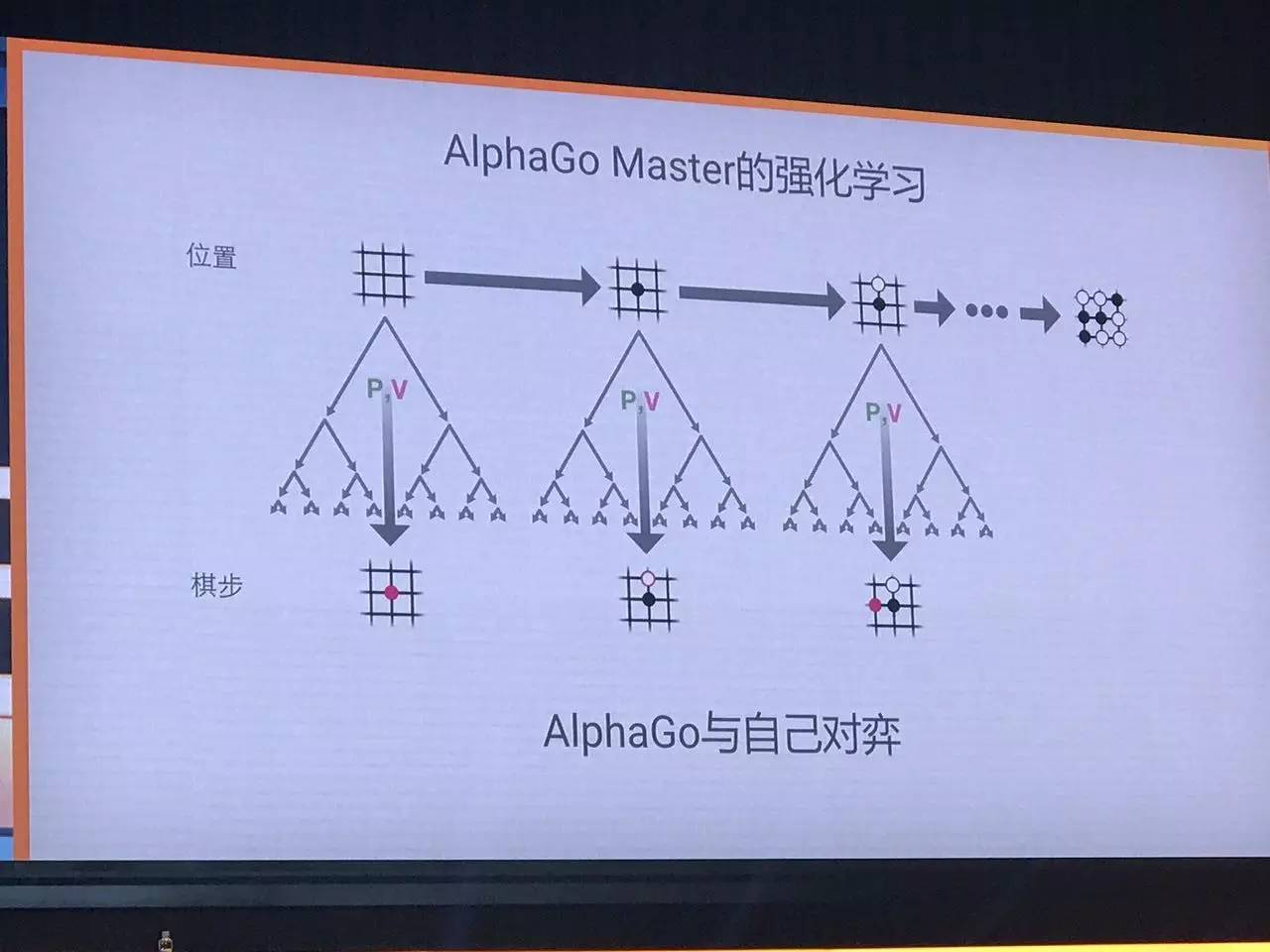
而使Master如此强大的原因之一,是我们使用了最好的数据——AlphaGo自我对弈的数据。所以,AlphaGo实际上成了自己的“老师”,每一代生成的数据都成为下一代、更强一代的训练材料。我们使用这一过程,训练了更强大的策略网络和价值网络。
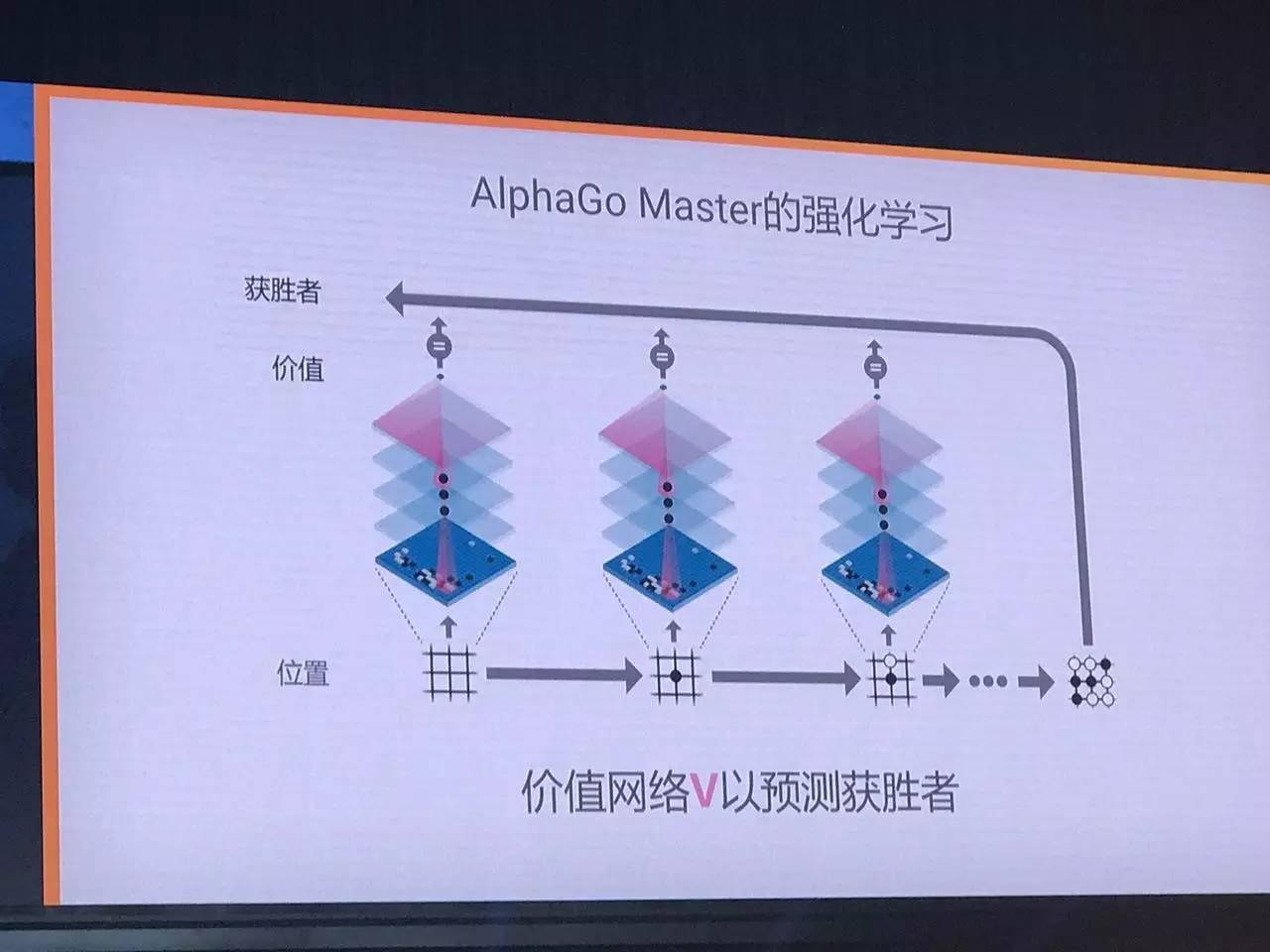
具体说,我们让AlphaGo自我对弈,也就是通过强化学习,生成大量数据,训练下一代的AlphaGo。这时,策略网络就使用它自己生成的数据,在不进行任何搜索的情况下,自己训练自己得出最强大的走法,由此得出了目前最强大的策略网络。 类似的,我们也这样训练价值网络,我们使用AlphaGo自我对弈后获胜的那些数据来作为训练样本,这些都是质量很高(最高)的样本,里面含有大量每局AlphaGo自我对弈中每一步走法赢率判断的信息。换句话说,新的价值网络会判断Master每一步的最终赢率是多少。
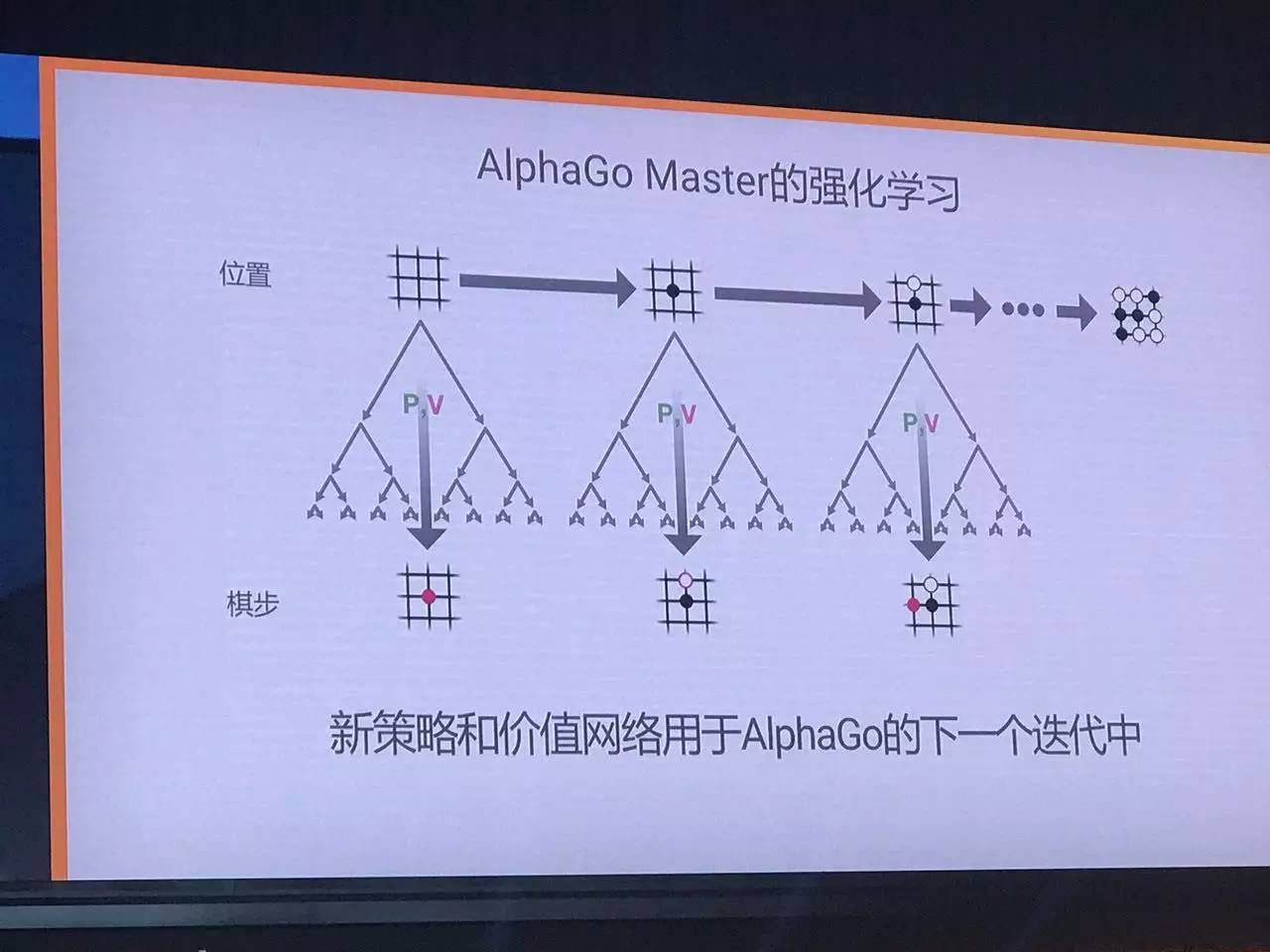
然后,我们将上述过程重复多次,不断得到新的价值网络和策略网络,AlphaGo也能不断做出更高效的搜索质量和更好地判断胜率。
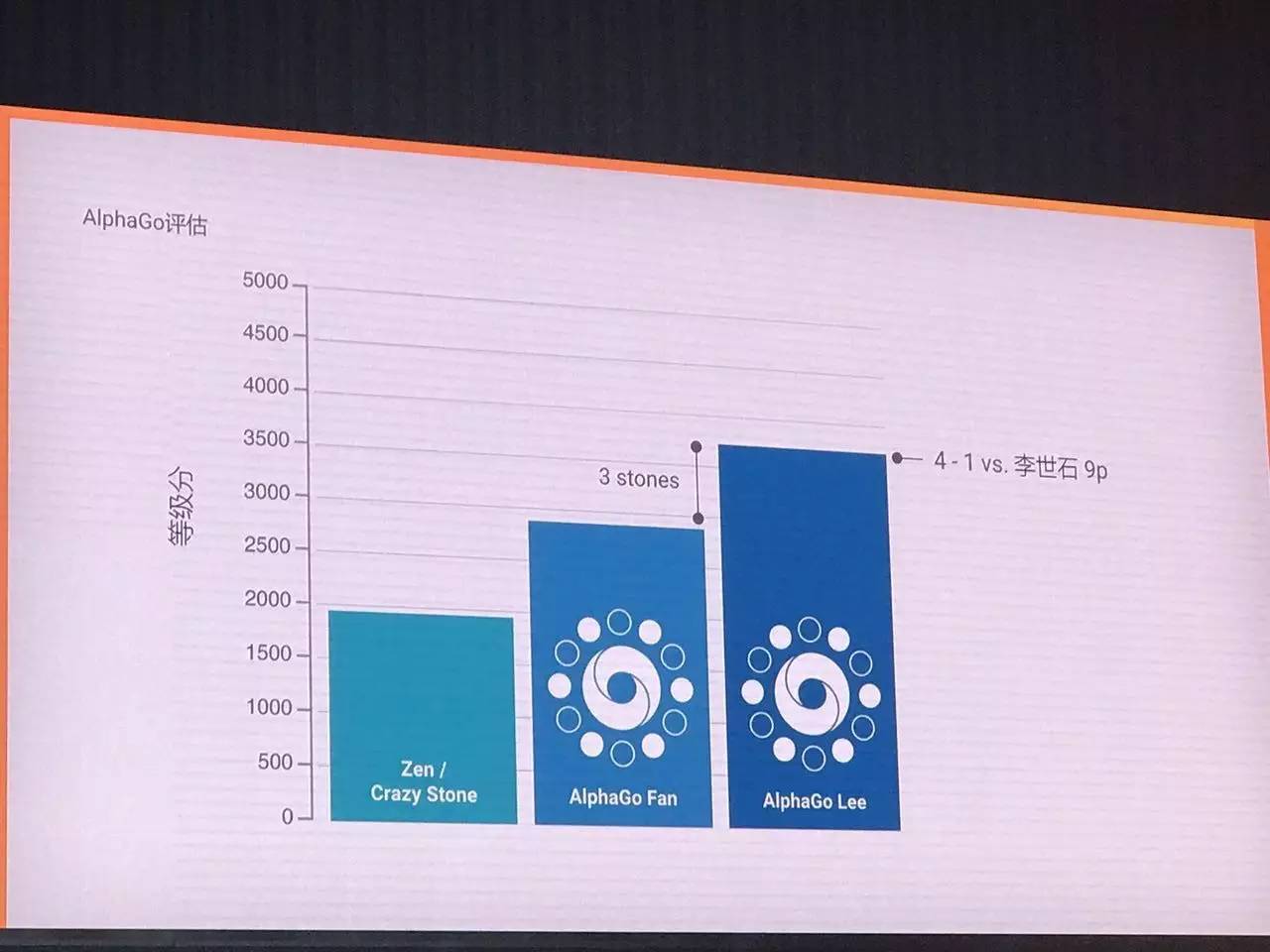
那么,我们怎么衡量AlphaGo的能力呢?我们最初用Zen和进行对比,后来是樊麾,再到李世石,以及线上对战平台。
但是,只通过自我对弈是无法找出AlphaGo的弱点的。这也是我们今天来乌镇对战柯洁的原因。当然,深度强化学习也不仅仅用在围棋上,还有游戏中。 (责任编辑:本港台直播) |