|
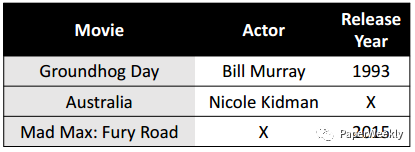
本期Chat是PaperWeekly第一次尝试与读者进行互动交流,一共分享和解读3篇paper,均选自2016年最值得读的自然语言处理领域paper,分别是: End-to-End Reinforcement Learning of Dialogue Agents for Information Access Dual Learning for Machine Translation SQuAD: 100,000+ Questions for Machine Comprehension of Text 1. End-to-End Reinforcement Learning of Dialogue Agents for Information Access 作者Bhuwan Dhingra, Lihong Li, Xiujun Li, Jianfeng Gao, Yun-Nung Chen, Faisal Ahmed, Li Deng 单位 School of Computer Science, Carnegie Mellon University, Pittsburgh, PA, USA Microsoft Research, Redmond, WA, USA National Taiwan University, Taipei, Taiwan 关键词 Dialogue Agent, Reinforcement Learning 文章来源 arXiv 问题 用强化学习构造一个端到端的任务驱动的基于知识图谱的对话系统。 模型 一个任务驱动的对话系统,一般通过自然语言与用户进行多轮交流,帮助用户解决一些特定问题,例如订机票或检索数据库等。一般由下面四部分组成: Language Understanding Module(LU): 理解用户意图并提取相关slots。例如用户想找一部电影,那么就需要提取出电影名称,演员,上映时间等相关slots信息。 Dialogue State Tracker: 追踪用户的目标和对话的历史信息。 Dialogue Policy: 基于当前状态选择系统的下一步action, 例如向用户询问电影上映时间的action是request(year)。 Natural Language Generator(NLG):将系统的action转化成自然语言文本。例如将request(year) 转换成:电影什么时候上映的? 在Dialogue Policy这一步,传统方法一般是生成一个类似SQL的查询语句,从数据库中检索答案,但是这会使模型不可微从而只能分开训练。本文使用了基于概率的框架,因此是可微的,从而实现了端到端的训练过程。 论文中用到的数据库,是来自IMDB的电影数据库。每一行代表一部电影,每一列是一个slot,信息有可能存在缺失。
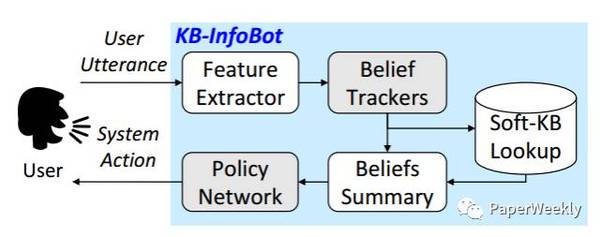
整体框架如下图:
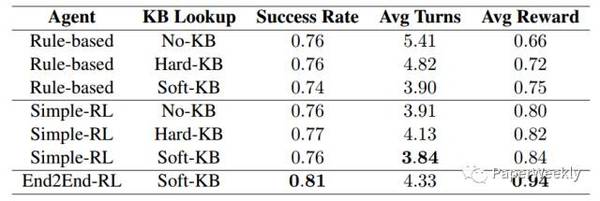
下面分别介绍各个部分: Feature Extractor 将用户每轮的输入文本转化成一个向量,这里使用了ngram词袋模型(n=2)。 Belief Trackers 用于追踪对话状态和历史信息。 这里针对每一列的slot,分别有一个belief tracker。每个belief tracker的输入是从feature extractor得到的向量,用GRU处理以后,得到一个状态向量。根据这个状态向量,分别计算得到两个输出:pj和qj。 pj是当前slot下所有值的概率分布,qj是用户不知道这个slot值的概率。 因为在和用户交互的过程中,应当尽可能询问用户知道的信息,询问用户不知道的信息对后面的查询没有任何意义。 Soft-KB Lookup 根据Belief Trackers的输出,计算数据库中每个值的概率分布。 Beliefs Summary 由Belief Trackers和Soft-KB Lookup,可以得到当前的对话状态向量st。st向量包含了数据库中所有值的概率分布户是否知识等信息,实在是太大了,atv,直接送给Policy Network会导致其参数过多,难以训练。因此这一步把slot-values转化成了加权的熵统计信息。 Policy Network 这里使用策略网络,根据Beliefs Summary的输入状态向量,来输出各个action的概率分布π。具体结构是GRU+全连接层+softmax的方式。 Action Selection 这里从策略分布π采样,得到下一步的action。如果action是inform(),说明到了对话的最后一步,需要给用户返回Top k的查询结果。这里按照Soft-KB Lookup步骤中得到的每一行电影的概率,进行采样来返回Top K候选。 NLG 这里的NLG部分和上面是独立的,使用了sequence-to-sequence模型,输入action,输出包含slot的对话模板,然后进行填充,得到自然语言文本。 训练 这里用的基于策略梯度的强化学习模型进行训练,目标是最大化reward的期望。最后一轮inform部分的reward是由正确答案在Top K候选中的排序位置决定,排序越靠前,reward越高。如果候选没有包含正确答案,那么reward是-1。 对话交互训练数据是通过一个模拟器从电影数据中采样生成得到。 Baselines End2End-RL:本文提出的模型。 Rule-based:Belief Trackers和Policy部分都是人工规则。 Simple-RL:只有Belief Trackers是人工规则,而Policy部分是基于GRU。 实验结果如下图:
相关工作 (责任编辑:本港台直播) |