|
准备数据集--对神经网络参数进行初始化--不断重复知道得到一些标准的东西--准备好进行下一次小的batch--定义如何计算损失--计算损失(前向)--计算梯度(反向)--升级神经网络参数--保存神经网络参数。
训练的精华内容:把典型的训练程序作为API,用户不需要手动写程序。
数据载入 支持从大型的数据库中载入预先定义的数据,比如,MNIST、CIFAR、PenTreeBank等等。
训练过程的序列化 什么是序列化:训练过的模型(也就是神经网络的架构和参数)、训练过程的状态。
序列化可以提高模型的可移植性 预训练模型的发布: 用户可以在自己的任务总使用与训练的模型 许多框架,包括Caffe、MXNet 和 TensorFlow 都推出了大的模型(比如,VGG, AlexNet 和ResNet) 虽然分享预训练模型的大型网站很少,比如说 Model Zoo,但是,许多作者还是会私下分享他们的模型。 从其他框架中引入预训练模型:比如,Chainer 支持Caffe 的 BVLC-official 参考模型
并行计算:模型的并行和数据的并行
在每一种模式中,深度学习框架应该有不同的表现。 在模型的衡量和推理中,不需要反向传播 一些操作,比如Dropout和Batch 正则化,在训练和衡量或者推理中,是不同的。 图计算的替代依赖于模式的不同
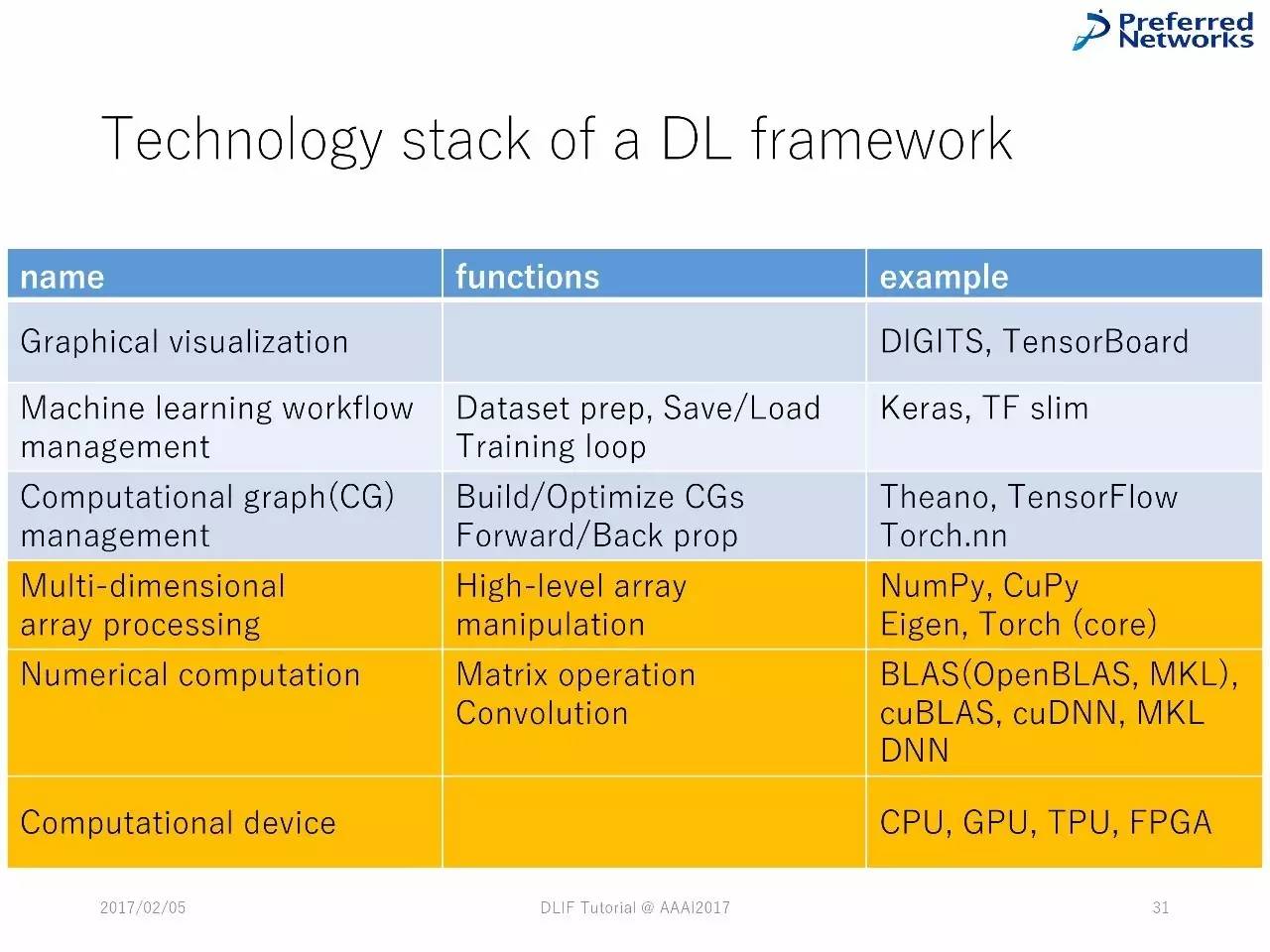
深度学习框架中的技术堆栈
图的可视化:帮助用户用更加简便的工具来开发模型。 设计、监测和分析都可以使用。
深度学习框架中的技术堆栈
GPU 支持:绝大多数深度学习中的计算包含了大型的矩阵乘法和函数应用,GPU可以加速这些计算。(在大多数的情况下)。 DL 框架可以在CPU 和 GPU 间无缝切换。一般来说,框架会通过隐藏的CUDA来支持GPU。
多维数组库(CPU/GPU) 负责数据节点中的具体计算 严重依赖于BLAS(CPU)或CUDA 工具(GPU) 第三方库:Tensorflow(CPU/GPU)、 NumPy (CPU)、PyCUDA(GPU)、 gpuarray (GPU)。 Scratch:ND4J,mshadow(MXNet),Torch,Cupy (Chainer) 大多数的GPU 数组库希望能在CPU和GPU中进行切换。
例子:Chainer/CuPy
使用哪一个设备? GPU是第一选择,但是,GPU 不是一个永远正确的选择。
Chainer 中的技术堆栈
TensorFlow 中的技术堆栈
Theano 中的技术堆栈
Keras中的技术堆栈
总结 绝大多数的深度学习框架的组件都有共通之处,由类似的技术堆栈组成。 (责任编辑:本港台直播) |