|
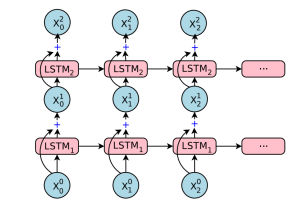
你或许还会注意到在第五层及以后,输入前面都会增加“+”这个符号。这是残差学习的一种形式,发生在第 5 层及以后。对于每 N+1 层来说,输入相当于 N 和 N-1 层的输出之和。实验证明,使用这种方法能够减少因为梯度消失(Vanishing Gradient)等问题而产生的不准确,梯度消失是很多深度学习应用中都会出现的问题。形象一些看,你可以将残差学习想象为跨层之间的信息保存,同时将整个深度网络“稳定”在一定范围内,不会从输入的信息太跑偏。
最后,你会发现在编码器输入的最后会有 <2es> 和 </s> 的符号。</s> 代表“输入结束”,<2es> 代表目标语言——在本文中也就是西班牙语。这是 GNMT 才会有的特殊方法,将目标语言也视为输入,以此提升翻译性能。 注意力模块和解码器
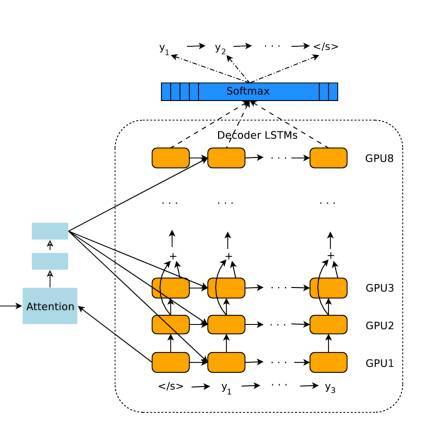
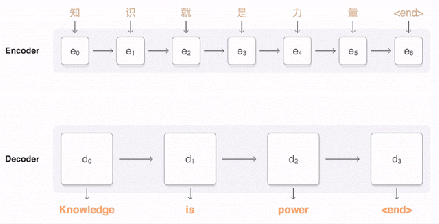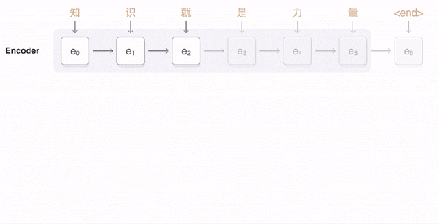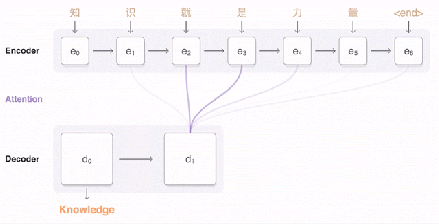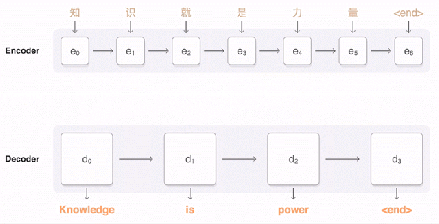
编码器产生一组有顺序的输出向量,然后它们被输入注意力模块和解码器的框架中。在很大程度上,解码器与编码器类似,在设计上都是堆叠的 LSTM 和残差连接。在这里细说一下不同的地方。 前面已经说过,GNMT 将整句话作为一个输入的整体。但是,对于解码器产生的每个 token,在输入的句子中的权重都是不一样的,这样考虑起来才更加自然。在你阅读的过程中,读过了的部分就会注意力就会转移到还没有阅读的内容上去。这部分工作是由注意力模块来负责的。注意力模块的输入实际上是编码器的全部输出,以及编码器堆栈中最后一个向量。这种方法使得注意力模块“了解”已经被翻译了的部分(以及已经翻译了多少),然后将解码器指向编码器输出的其他部分。 解码器 LSTM 堆栈根据编码器的输入和注意力模块的指向,持续输出向量。这些向量会被输入 Softmax 层(Softmax Layer)。你可以将 Softmax 层想象为概率分布生成器(Probability distribution-generator)。从 LSTM 最上层输入的向量开始,Softmax 层会给每一个可能的 token 分派一个概率(需要记住的是,目标语言已经提供给编码器了,因此这个信息已经传递了)。被分派到概率最大的那个token最终被输出。 整个过程在解码器/Softmax 决定当前token为无(即句子结尾)时停止。解码器不需要执行相当于输出向量的一系列步骤,因为它始终对所有计算步骤都保持着注意。 总的来说,上述过程可视化以后就是下面这个样子。
训练以及零数据翻译(Zero-Shot Translation) 整个框架(编码器+注意力模块+解码器)使用大量数据训练,这些数据包括输入的、经过翻译的句子对。系统架构通过将输入的语言转变为相应的向量来“了解”输入的语言。输出的语言(即目标语言)也被作为参数提供给系统。深度 LSTM 的美妙之处在于神经网络自己学会所有的计算,使用一类被称为反向传播/梯度下降的算法。
GNMT 团队的另一个惊人发现是:仅仅是将目标语言作为输入提供给框架,系统就能够进行零数据翻译!简单说就是,在你训练系统将英语翻译为日语,以及将英语翻译为韩语的过程中,系统自己就学会了将日语翻译为韩语。实际上,这正是 GNMT 团队最重大的成就。 从中我们可以知道,编码器实际上产生了一种通用语言(interlingua)。当我用任何语言说“狗”的时候,你脑海中都会产生一种可亲的犬科动物的形象,也就是“狗”的概念。编码器就产生了这种“概念”,与具体的语言无关。这也是为什么有些人评论说,谷歌的 AI 发明了自己的语言。 (责任编辑:本港台直播) |