|
近日,2016中国大数据技术大会(Big Data Technology Conference 2016)在京隆重举行。本次会议涵盖了大数据分析与生态系统、推荐系统等16场专题技术和行业论坛,来自中国科学院、蚂蚁金服、一点资讯等公司和机构的众多国内外大数据专家参会并发表演讲。
在大会现场,一点资讯大数据平台研发总监田超详细阐述了用户点击反馈背后的系统设计,并根据行业现有的种种问题,分享了一点资讯推荐系统背后大规模实时点击反馈系统的设计。 他指出,作为一家融合了搜索引擎和个性化推荐引擎技术的全网化内容平台,一点资讯可以根据用户不同使用场景、订阅频道下的点击反馈形成数据矩阵,对数据进行深层次挖掘,并通过大规模实时点击反馈系统和大规模机器学习进行智能推荐,引领兼具共性与个性的移动价值阅读潮流,使用户阅读体验不断提升。 以下是演讲节选: 大家下午好,我是来自一点资讯的田超,很高兴今天与大家分享一点资讯关于推荐系统后台的一些心得。
首先给大家介绍一下一点资讯的数据。目前,一点资讯的日活达4800万。与此同时,这里需要特别指出,一点资讯主动订阅用户数已达4700万。作为一家融合了搜索和个性化推荐的技术驱动型的全网化内容平台,与单纯搜集和反馈用户的历史浏览行为不同的资讯平台不同,我们更注重和鼓励用户主动表达,通过全网化的智能客户端,深度挖掘用户点击阅读背后的真实兴趣,不仅为大家带来有趣、有料也能提供有用、有品的价值内容。 实时点击反馈数据应用,让服务更智能化 熟悉搜索和推荐系统架构的朋友都知道,一直以来,这两种系统大都分工进行,但实际上在数据部分,二者存在很多可融合之处。这也是启发我们做出一套能够真正把搜索、推荐、广告等环节连接在一起,形成完整智能体验的推荐服务系统的基础。
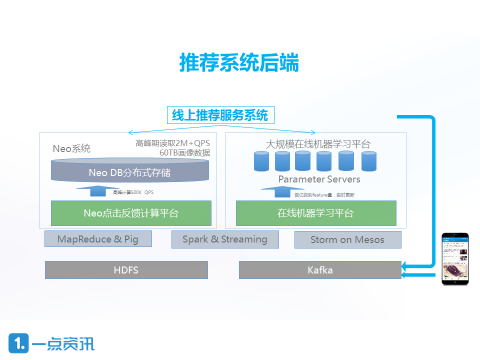
一点资讯数据团队负责一点推荐平台背后的大规模机器学习基础设施的开发,推荐系统的后端主要是由基于用户画像的GBDT推荐平台和基于大规模离散LR的在线学习平台组成。今天我们会为大家介绍其中的一部分,也就是上图左边所示的大规模实时点击反馈平台的设计。 关于点击反馈的数据在每家后台系统上大概都有这样三部分的应用:第一部分是实时画像中的后验指标,包括了用户画像,内容画像和频道画像等;第二部分是实时的数据分析,让我们在做不同实验时,了解到不同人群、文章点击率的变化;第三部是在线的机器学习,后面我会详细介绍。 对于客户端来说,虽然推荐服务系统为我们带来很多便利,但同时也面临不少问题和挑战,下面我将从一点资讯的架构设计为例,为大家分别阐述五个方面的主要问题以及解决方式。 问题1:如何统一各种近似的实时Pipeline 第一个问题就是近似的pipeline大家怎么样去统一?做实时计算时,大家常常发现你的Storm、spark跑着各种各样相近但又不同的作业,这些作业中80%运算是相同的。这对系统实时更新、开发成本都会造成一定损耗。 在一点资讯内部,我们设计了一套叫Neo的点击反馈平台系统,统一了主要的实时点击反馈计算逻辑。 Neo系统的核心数据结构是一个Multi-Dimensional Matrix(多维矩阵),用以描述用户在各个维度和粒度的兴趣属性和基础属性两部分,可以在不同维度和数据粒度上进行各种聚合运算。其次,我们围绕着核心数据结构构造了整个运行时的framwork(框架),可以支持用户自定义自己的算子,也因此节省了对数据流的压力。 问题2:实时计算和离线计算的统一 第二个问题说怎样实时计算和离线计算的统一? 实时计算与离线计算的统计是流式计算领域里的研究热点之一,对于我们的生产工作来说也有着比较重要的实际意义,市面上有一些开源和技术和论文包括Spark、SummingBird、Google DataFlow等都对如何实现自己的解决方案。 (责任编辑:本港台直播) |