|
:COO、执行总编、主编、高级编译、主笔、运营总监、客户经理、咨询总监、行政助理等 9 大岗位全面开放。 简历投递:j[email protected] HR 微信:13552313024 新智元为COO和执行总编提供最高超百万的年薪激励;为骨干员工提供最完整的培训体系、高于业界平均水平的工资和奖金。 加盟新智元,与人工智能业界领袖携手改变世界。 【新智元导读】基于第一印象/表象的性格自动分析是计算机视觉和多媒体领域中一类非常重要的研究问题。近日欧洲计算机视觉大会(ECCV 2016)ChaLearn Looking at People Workshop 举办了一场全球范围的(视频)表象性格分析竞赛,来自南京大学计算机系机器学习与数据挖掘所(LAMDA)的参赛队 NJU-LAMDA 在 86 个参赛队伍中斩获第一,本文为该队 Team Director 魏秀参的经验分享。 英文中有句谚语叫:"You never get a second chance to make a first impression."(你永远没有第二个机会去改变你的第一印象。)一个人的第一印象可以用来快速判断其性格特征(Personal traits)及其复杂的社交特质,如友善、和蔼、强硬和控制欲等等。因此,在人工智能大行其道的当下,基于第一印象/表象的性格自动分析也成为计算机视觉和多媒体领域中一类非常重要的研究问题。 前不久,欧洲计算机视觉大会(ECCV 2016)ChaLearn Looking at People Workshop 就举办了一场全球范围的(视频)表象性格分析竞赛(Apparent personality analysis)。历时两个多月,我们的参赛队(NJU-LAMDA)在 86 个参赛者,其中包括有印度“科学皇冠上的瑰宝”之称的 Indian Institutes of Technology (IIT)和荷兰名校 Radboud University等劲旅中脱引而出,斩获第一。在此与大家分享我们的竞赛模型和比赛细节。 问题重述 本次 ECCV 竞赛提供了平均长度为 15 秒的 10000 个短视频,其中 6000 个为训练集,2000 个为验证集,剩余 2000 个作为测试。比赛要求通过对短视频中人物表象(表情、动作及神态等)的分析来精确预测人的五大性格特质,即 Big Five Traits,其中包括:经验开放性(Openness to experience)、尽责性(Conscientiousness)、外向性(Extraversion)、亲和性(Agreeableness)和情绪不稳定性(Neuroticism)。视频示例如下所示:
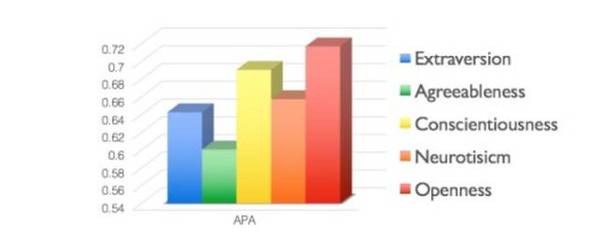
竞赛数据中五大性格特质的真实标记(Ground truth)通过 Amazon Mechanical Turk 人工标注获得,每个性格特质对应一个0~1之间的实值。
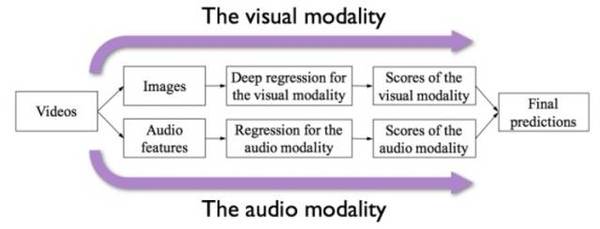
我们的方法 由于竞赛数据为短视频,我们很自然的把它作为双模态(Bimodal)的数据对象来进行处理,其中一个模态为音频信息(Audio cue),另一个则为视觉信息(Visual cue)。同时,需预测的五大性格特质均为连续值,因此我们将整个问题形式化为一个回归问题(Regression)。我们将提出的这个模型框架称作双模态深度回归(Deep Bimodal Regression,DBR)模型。下面分别从两个模态的处理和最后的模态融合来解析 DBR。
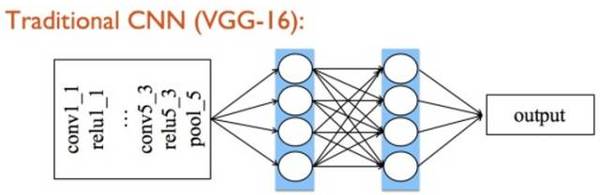
视觉模态 在视觉模态中,考虑到对于短视频类数据,时序信息的重要程度并不显著,我们采取了更简单有效的视频处理方式,即直接将视频随机抽取若干帧(Frame),并将其作为视觉模态的原始输入。当然,在 DBR 中,视觉模态的表示学习部分不能免俗的使用了卷积神经网络(Convolutional Neural Networks,CNN)。同时,我们在现有网络基础上进行了改进,提出了描述子融合网络(Deor Aggregation Networks,DAN),从而取得了更好的预测性能。 以 VGG-16 为例,传统 CNN 经过若干层卷积(Convolutional)、池化(Pooling)的堆叠,其后一般是两层全链接层(Fully connected layers)作为网络的分类部分,最终输出结果。
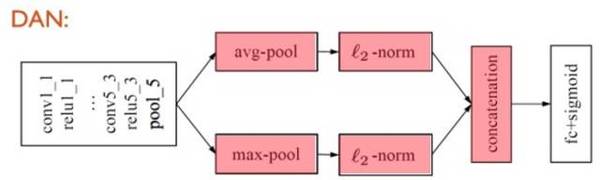
受到我们最近工作[2]的启发,在 DBR 视觉模态的 CNN 中,我们扔掉了参数冗余的全链接层,取而代之的是将最后一层卷积层学到的深度描述子(Deep deor)做融合(Aggregation),之后对其进行 L2 规范化(L2-normalization),最后基于这样的图像表示做回归(fc+sigmoid作为回归层),构建端到端(End-to-end)的深度学习回归模型。另外,不同融合方式也可视作一种特征层面的集成(Ensemble)。如下图,在 DAN中,我们对最后一层卷积得到的深度描述子分别进行最大(Max)和平均(Average)的全局池化(Global pooling)操作,之后对得到的融合结果分别做 L2 规范化,接下来将两支得到的特征级联(concatenation)后作为最终的图像表示(Image representation)。
|