|
消费品企业应该如何使用内部产生以及外部采集的数据,像互联网公司一样建立用户画像与会员体系,以数据驱动的方式进行精细化的生产,运营和销售?
传统的管理咨询公司,虽然有无数顶尖的大脑,但是他们的大脑只靠Excel的辅助,这样的算力,能不能满足上述的需求? 无论是提供商品还是服务,用户画像都是数据挖掘工作的重要一环。一个准确和完整的用户画像甚至可以说是许多互联网公司赖以生存的宝贵财富。 我们也已经听过了无数用户画像的神奇功能和成功案例: 比如亚马逊,淘宝的机器学习团队使用用户的浏览行为,购物车状态和购买记录开发关联推荐系统,使点击率和销量大幅提升;比如应用市场根据过往APP安装记录记对每个使用者进行精准推荐;再比如音乐,图书和新闻网站通过协同过滤的方式为用户呈现个性化的定制内容。 而管理咨询公司只能通过人肉的市场调研和抽样的方式,进行粗糙的用户画像。 对于消费品公司而言,虽说用户行为数据的丰富程度和互联网产品相比稍显逊色,但也拥有庞大的用户信息和交易数据沉淀散落在各个IT系统中,而且更真实,噪音更少。只不过在传统消费品公司里会编程,会处理数据的人要比互联网公司少太多太多。 在我们深入了解了这些用户信息和交易数据,并对它们进行了清洗,汇总,打通之后,发现数据质量要比我们想象的好很多,可以支撑许多有意思的用户画像的建立。在这里我会分享一些画像的流程和思路,供大家参考。 2. 数据标签化 用户画像的底层是机器学习,那么无论是要做客户分群还是精准营销,都先要将用户数据进行规整处理,转化为相同维度的特征向量,诸多华丽的算法才可以有用武之地,像是聚类,回归,关联,各种分类器等等。 对于结构化数据而言,特征提取工作往往都是从给数据打标签开始的,比如购买渠道,消费频率,年龄性别,家庭状况等等。好的特征标签的选择可以使对用户刻画变得更丰富,也能提升机器学习算法的效果(准确度,收敛速度等)。 我们在项目中根据不同维度提取了数十个多个标签,图7展示了其中的一部分。这些标签主要有三个来源: 一个类是在IT系统中可以取得的信息,比如办会员卡时留下的信息(性别,年龄,生日),购买渠道,积分情况等;第二类是可以通过计算或是统计所获得的,比如用户对某类促销活动的参与程度,对某种颜色/款式商品的偏好程度,是否进行过跨品牌的购买等;第三类则是通过推测所得,比如送货地址中出现“宿舍”,“学校”,“大学”等字样,则用户身份可以推测为学生,出现“腾讯大厦”,“科技园”等信息时,则可判断是上班族,并有很大概率是技术从业者。 在标签的设计上也带有较强的行业性,比如是否偏好购买当季爆款或是新品多于经典款(时尚度);是否更倾向购买低价或打折商品(价格敏感度);是否喜欢购买高价商品或限量版(反向价格敏感度)。
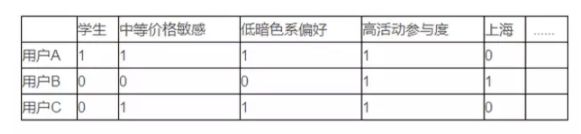
对于已经打好的标签,根据不同的分析场景进行离散化,或将分类类型的标签拆成多个0/1标签,就可以进行一些机器学习的建模了,比如聚类,分类,预测,或者关联性分析,最终生成的向量维度在数千个。 说到这里,咨询公司里面的Excel是不是已经开始快宕机了? 3. 关联性分析 关联性分析(Association rule learning)是在零售行业中应用最广泛的一种机器学习方法,直播,营销学里经典的“啤酒/尿布”(超市里购买尿布的消费者往往同时购买啤酒)案例也已经是家喻户晓。 虽然后来被证实这是一个为了教学目的而虚构出来的案例,但从其上镜率也可以看得出关联性分析在零售领域的重要程度,或许这个例子在国内改成“泡面/火腿肠”会更亲切。 关联性分析的相关文章有非常多,支持度(Support),置信度(Confidence)和增益(Lift)这些基本概念的介绍在这里就不赘述了,各位如果有兴趣可以参见Wikipedia的Association rule learning页面。 和购物篮关联规则不同,我们数据挖掘过程中的基本单位是用户,而特征向量则是基于提取出的用户标签而构建的,下表是一个简单的示例。 第一个例子
我们获得了一个NxM的特征矩阵,N为用户数,量级在百万级,M为特征维度,约数千个的二元标签。 基于这个特征矩阵我们使用了最基础的Apriori算法计算相关度,并在支持度,置信度和增益三个层面设置threshold,输出符合要求的关联规则。 (责任编辑:本港台直播) |