|
编者注:人工智能抢人类饭碗的趋势越来越明显了,最近,它又瞄准了一个新行业,而且一出手就比该行业专家们做的好。 主角还是 AI 大咖谷歌DeepMind,这次他们与英国牛津大学合作,通过机器学习大量的 BBC 节目,来学习一项全新的技能:唇读术。可怕的是,人工智能不仅学会了,而且让唇读专家们自愧不如。 唇读是人类一项独特的技艺,也是非常困难的一件事,它对于语言语境和知识理解的要求并不亚于视觉上的线索,然而 AI 又做到了。
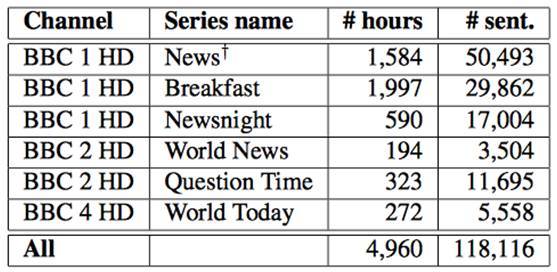
AI 系统的学习对象是近 5000 小时的 BBC 各类节目,包括 Newsnight、BBC Breakfast、Question Time 等,所有视频资料加起来约有 11.8 万句话。 谷歌DeepMind 和牛津大学的联合研究团队使用了 2010 年 1 月至 2015 年 12 月间的电视节目素材对 AI 系统进行训练,然后使用 2016 年 3 月- 9 月间播出的节目进行 AI 性能测试。
BBC节目数据库。从左至右分别为:频道、节目名称、小时数、句数 通过观察节目中说话者的唇形,AI 系统可以准确解读出文字,比如下面这些比较“拗口”的句子:“我们知道也将有上百位记者会出席”(We know there will be hundreds of journalists here as well),以及“根据国家统计局的最新统计数据”(According to thelatest figures from the Office of National Statistics)。 DT 君试读了以上英文语句,发现唇形变化其实并不明显,而且电视节目中的语速是非常快的,难度可想而知。
BBC节目数据库中无字幕原片
由谷歌DeepMind AI系统通过唇读同步的字幕 AI能力再升级 测试结果的具体数据可能更能说明问题:在 2016 年 3 月-9 月的节目库中随机选取的 200 个说话场景唇读对比测试中,人类专家的完全准确率为12.4%,而AI的完全准确率为46.8%。 而且 AI 所犯错误中有很多其实无关紧要,比如在复数后面漏掉一个“s”之类。不过哪怕是这样,AI 还是完虐了人类唇读专家。 人工智能业内专家称,“这绝对是建构全自动唇读系统的第一步!现有的各类庞大数据库完全可以支持深度学习技术的发展。”
上方彩色图片为BBC节目数据库原始静态图片,下方黑白图片为两个不同的人说出“afternoon”(下午)这个单词时的唇型 两周前,牛津大学曾开发了一个类似的深度学习系统LipNet,这套系统当时就已93.4%对52.3%大比分击败了人类唇读专家,但还不太说明问题,毕竟,LipNet和人类的竞赛是基于GRID语料库,这个数据库只包含51个特殊词汇。 而DeepMind这次选取的BBC节目数据库却包含了惊人的17500个特殊词汇,对人工智能来说,这无疑是艰巨的挑战。
GRID语料库中的音视频数据相对简单得多 除此之外,BBC节目数据库中包含了人类在正常说话时使用的各种语法,而GRID语料库的33000个句子都采用相同表达,这使得句子很容易被预测,难度也相对低得多。 DeepMind和牛津大学的研究团队将开放BBC节目数据库供同行使用。来自LipNet的 Yannis Assael 表示将率先使用这一数据库来训练自己的唇读AI系统。 把嘴唇排列起来 如果要通过 BBC 节目这一类的视频数据库来训练自动唇读系统,必须要让机器预先学习每一个视频片段。可问题是,节目中的视频流与音频流往往不是完全同步的,甚至会出现多达1秒左右的时间差。 简单地说,这会让机器彻底蒙圈,因为视频里出现的唇形没办法和音频完美贴合,机器就无法将某一特定唇形和其发音对号入座。这样看来,AI 学习唇读术好像是不可能的。
|