|
KBP2016 是由 NIST(National Institute of Standards and Technology,美国国家标准与技术研究院)指导、美国国防部协办的赛事,主要任务为从自然书写的非结构化文本中抽取实体,以及实体之间的关系。 美国当地时间 2016 年 11 月 15 日,NIST 揭晓 KBP2016 EDL 大赛结果。其中,科大讯飞包揽了本届 EDL 比赛的冠亚军。 机器之心第一时间采访了科大讯飞研究院研究员刘丹,从 KBP2016 比赛情况、KBP 任务难点、以及讯飞的 NLP 方向进展展开话题。以下为采访实录。 机器之心:能请您介绍一下 KBP 这个任务的情况吗? 刘丹:本次我们参加的是 KBP 国际公开评测任务,比赛由 NIST 资助,从 2009 年起举办至今。 KBP(Knowledge base population)任务的主要目标是知识库扩展和填充,研究的主要内容是传统的结构化知识库如 Freebase,目前它的构建绝大多数都要依靠人的编辑工作。知识库中描述的信息是物理世界的命名实体和实体之间关系的抽取,如「克林顿和希拉里之间是夫妻关系」、「克林顿毕业于耶鲁法学院」这样一个个实体的关系。但人工编辑有两个问题,一是工作量较大,再就是可能出现错误和时效性的问题。
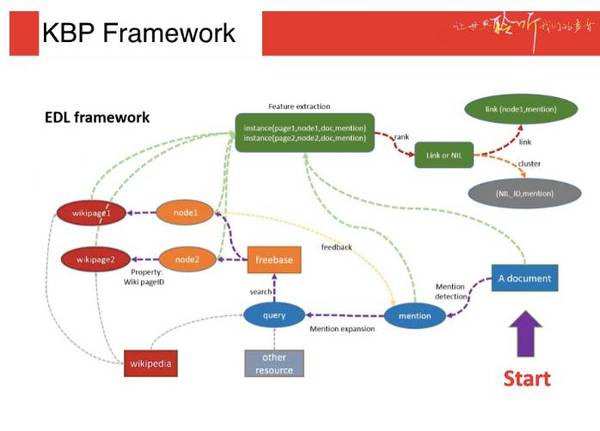
KBP 任务框架,资料来自科大讯飞 很久以来大家都在思考,人可以通过阅读新闻和书本这样的文本语料获得相关知识,机器可不可以?KBP 公开任务的研究目标,是让机器可以自动从自然书写的非结构化文本中抽取实体,以及实体之间的关系。我们今年参加的 EDL(Entity Discovery and Linking)命名实体的发现和连接任务所做的事情,是从自然语言的文本中抽取命名实体,标注它们的类型及实体与已有知识库之间的对应关系。从 2015 年开始,这个任务采用了中文、英文、西班牙文三个语种,需要找到三个语种的文本语料中的实体,并连接在一起。中文的「克林顿」要与英文的「Clinton」、西班牙文的「Clinton」连接到 Freebase 的同一个实体上。 机器之心:参赛方都有哪些公司、学校或者企业? 刘丹:学校居多,也有一些公司的研究机构。今年的 KBP 比赛 EDL 任务中,参加的学校有卡耐基梅隆、UIUC、伦斯勒理工,还有很多其他的学校。以企业名义参加的有 IBM,国内的机构有国防科技大、北京邮电大学和浙江大学。 机器之心:讯飞在 KBP 任务的多个指标中获得了第一,这些指标指哪些? 刘丹:命名实体连接这个项目分为很多子项目,一个是将三个语种放在一同统计,需要将不同语言的相同实体连接在一起;一个是将三个语种各自统计的指标,统计指标包括命名实体发现的正确率和命名实体连接的正确率。最终我们在整个比赛任务中的绝大多数指标都是第一,其中三个语种总体的指标是最高的,与其他参赛系统相比有比较显著的优势。单独的三个语种指标中,命名实体发现的部分都是第一。连接这部分中文我们是最高的,英文和西班牙文是第二。 机器之心:命名实体发现和命名实体连接发现的难点在哪里? 刘丹:命名实体发现中部分是 NLP 传统的命名实体标注任务,但 KBP 任务同其有两个区别: 一个是传统命名实体标注不允许有嵌套关系,如提到「中国科学技术大学」时,「中国科学技术大学」就是一个命名实体;KBP 则需要在文本中抽取更多细节的关系,不仅要将「中国科学技术大学」的「中科大」标注出来,同时「中国」也要标注出来,命名实体有一定的嵌套关系。除此之外,名词性的实体如「中国科大」、「科大讯飞」、「机器之心」都是一个个独立的名字(专有名词),这样的名字更容易标注;名词性的普通名词短语如「中国人」、「美国人」、「中国的公司」,这样的名词性实体需要与一般的名词短语区分开。 另外 KBP 任务需要标注的是有意义的名词性实体,如「XX 作为一个中国人」,这里的「中国人」是有明确指代的,所以需要标注;泛指性的如「中国人可以发怒了」,这里的「中国人」是不允许标注的。 KPB 任务更符合人对于事物类别的区分判断,有的内容是无法从语言语法的角度区分的,这让命名实体发现具有了比较大的难度。 (责任编辑:本港台直播) |