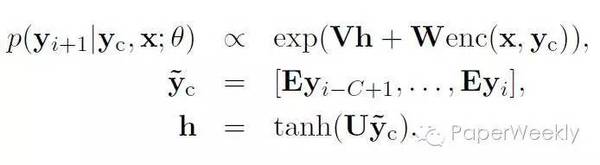|
文本摘要是自然语言处理的一大经典任务,研究的历史比较长。随着目前互联网生产出的文本数据越来越多,文本信息过载问题越来越严重,对各类文本进行一个“降维”处理显得非常必要,文本摘要便是其中一个重要的手段。传统的文本摘要方法,不管是句子级别、单文档还是多文档摘要,都严重依赖特征工程,随着深度学习的流行尤其是seq2seq+attention模型在机器翻译领域中的突破,文本摘要任务也迎来了一种全新的思路。本期PaperWeekly将会分享4篇在这方面做得非常出色的paper: 1、A Neural Attention Model for Abstractive Sentence Summarization, 2015 2、Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond, 2016 3、Neural Summarization by Extracting Sentences and Words, 2016 4、AttSum: Joint Learning of Focusing and Summarization with Neural Attention, 2016 1、A Neural Attention Model for Abstractive Sentence Summarization作者 Rush, A. M., Chopra, S., & Weston, J. 单位 Facebook AI Research / Harvard SEAS 关键词 Neural Attention, Abstractive Sentence Summarization 文章来源 EMNLP 2015 问题 这篇来自Facebook的paper的主题是基于attention based NN的生成式句子摘要/压缩。
模型 该工作使用提出了一种encoder-decoder框架下的句子摘要模型。
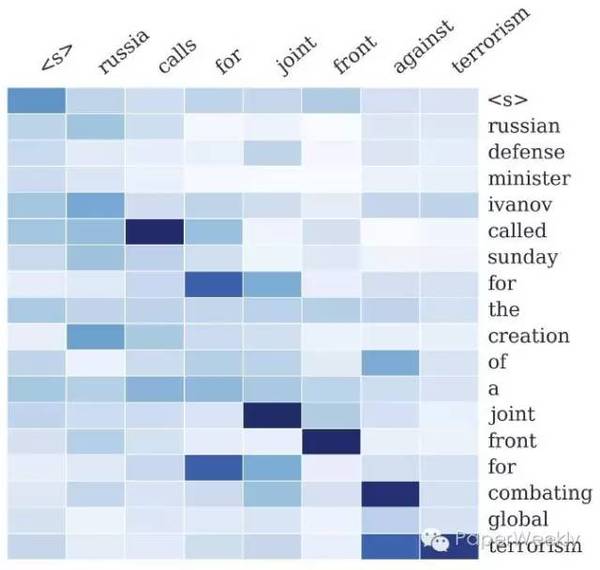
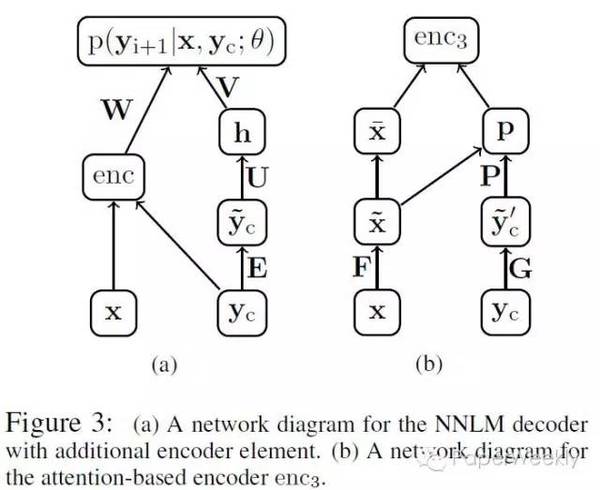
作者在文章中介绍了三种不同的encoding方法,分别为: Bag-of-Words Encoder。词袋模型即将输入句子中词的词向量进行平均。 CNN encoder Attention-Based Encoder。该encoder使用CNN对已生成的最近c(c为窗口大小)个词进行编码,再用编码出来的context向量对输入句子做attention,从而实现对输入的加权平均。 模型中的decoder为修改过的NNLM,具体地:
式中y_c为已生成的词中大小为c的窗口,与encoder中的Attention-Based Encoder同义。 与目前主流的基于seq2seq的模型不同,该模型中encoder并未采用流行的RNN。 数据 该文章使用了English Gigaword作为语料,选择新闻中的首句作为输入,新闻标题作为输出,以此构建平行语料。具体的数据构建方法参见文章。此外,该文章还使用了DUC2004作为测试集。 简评 在调研范围内,该文章是使用attention机制进行摘要的第一篇。且作者提出了利用Gigaword构建大量平行句对的方法,使得利用神经网络训练成为可能,之后多篇工作都使用了该方法构建训练数据。 2、Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond作者 Nallapati, Ramesh, et al. 单位 IBM Watson 关键词 seq2seq, Summarization 文章来源 In CoNLL 2016 问题 该工作主要研究了基于seq2seq模型的生成式文本摘要。 该文章不仅包括了句子压缩方面的工作,还给出了一个新的文档到多句子的数据集。 模型
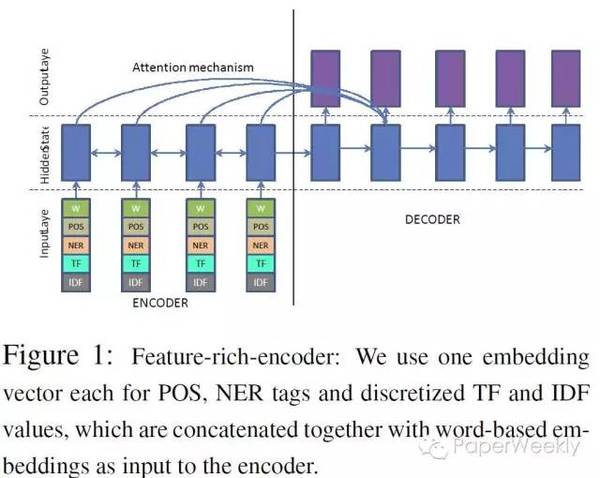
该文章使用了常用的seq2seq作为基本模型,并在其基础上添加了很多feature: Large Vocabulary Trick。 参见Sébastien Jean, Kyunghyun Cho, Roland Memisevic, and Yoshua Bengio. 2014. On using very large target vocabulary for neural machine translation. CoRR, abs/1412.2007. 添加feature。例如POS tag, TF、IDF,atv, NER tag等。这些feature会被embed之后与输入句子的词向量拼接起来作为encoder的输入。 pointing / copy 机制。使用一个gate来判断是否要从输入句子中拷贝词或者使用decoder生成词。参见ACL 2016的两篇相关paper。 Hierarchical Attention。这是用于文章摘要中多句子的attention,思路借鉴了Jiwei Li的一篇auto encoder的工作。大致思路为使用句子级别的weight对句子中的词进行re-scale。 数据English Gigaword DUC 2004 提出了CNN/Daily Mail Corpus 简评 (责任编辑:本港台直播) |