|
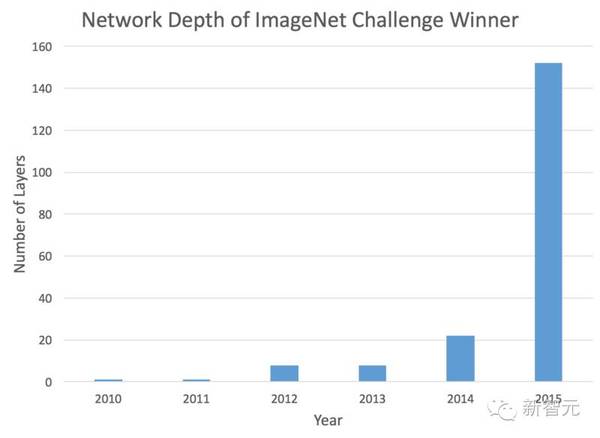
:COO、执行总编、主编、高级编译、主笔、运营总监、客户经理、咨询总监、行政助理等 9 大岗位全面开放。 简历投递:j[email protected] HR 微信:13552313024 新智元为COO和执行总编提供最高超百万的年薪激励;为骨干员工提供最完整的培训体系、高于业界平均水平的工资和奖金。 加盟新智元,与人工智能业界领袖携手改变世界。 【新智元导读】在许多任务中,神经网络越深,性能就越好。最近几年神经网络的趋势是越来越深。几年前最先进的神经网络还仅有12层深,现在几百层深的神经网络已经不是稀奇事了。本文中作者介绍了三个非常深的神经网络,分别是ResNet、HighwayNet和DenseNet,以及它们在Tensorflow上的实现。作者用CIFAR10数据集训练这些网络进行图像分类,在一小时左右的训练之后均实现了90%以上的精度。 神经网络设计的趋势:Deeper 谈到神经网络设计,最近几年的趋势都指向一个方向:更深。几年前最先进的神经网络还仅有12层深,现在几百层深的神经网络已经不是稀奇事了。对许多应用来说,神经网络越深,性能就越好,这在物体分类任务中影响最显著。当然,前提是它们能被恰当地训练。本文中我将介绍三个最近的深度学习网络背后的逻辑,分别是ResNet、HighwayNet和DenseNet。它们都能克服传统网络设计上的限制,使深度网络更容易训练。我也会提供在Tensorflow上实现这些网络的代码。
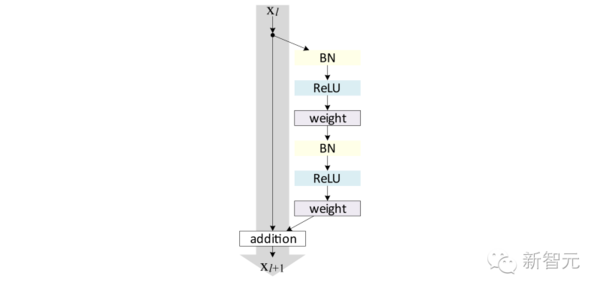
ImageNet竞赛胜出者的网络层数。网络越来越深的趋势非常明显。 为什么简单地加深网络并不管用? 设计深度网络的第一直觉可能是简单地把许多基本构建块(例如卷积层或全连接层)堆叠在一起。某种程度上这可以管用,但随着传统网络变得更深,网络性能会迅速下降。这是由于神经网络用反向传播的方式训练。训练时,梯度信号必须从网络最顶层反向传播到最底层,以确保网络本身能够正确更新。在传统网络中,当梯度信号通过网络的每一层,梯度会略微减小。对于只有几层的网络来说,这不成问题。但是对于有几十层的网络来说,当信号终于到达网络的最底层时,梯度信号已经差不多消失了。 因此,问题是设计一个神经网络,atv直播,其中梯度信号可以更容易通过有着几十、甚至几百层深的网络的所有层。这是本文中讨论的当前最先进的网络(ResNets,HighwayNets和DenseNets)背后的目标。 残差网络(Residual Networks) 残差网络(Residual Network),或ResNet,是一种可以用最简单的方式解决梯度消失(vanishing gradient)问题的网络结构。如果在梯度信号的反向传播中出现问题,直播,为什么不为网络的每一层设置一个短路通道(shortcut),使信号的通过更顺畅呢?在传统网络中,层的激活定义如下: y = f(x) 其中f(x)可以是卷积(convolution)、矩阵乘法(matrix multiplication)或批规范化(batchnormalization),等等。当信号反向传播时,梯度必须通过f(x),由于其中包含非线性而可能导致麻烦。反之,在ResNet中每层的实现如下: y = f(x) + x 后面的“+ x”即是短路(直连)通道,它允许梯度信号直接向后传递。通过这些层的stack,理论上梯度传递可以“跳过”所有中间层,直接到达最底层,而且不会发生梯度消减。 虽然理论上是这样,但实际的实现会更复杂。最新的ResNet中, f(x) + x采用的形式如下:
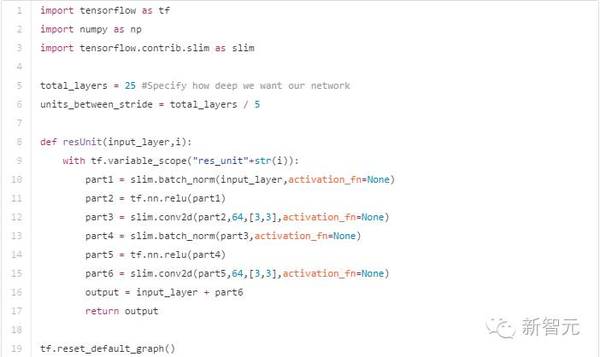
ResNet单元结构。BN指批规范化,Weight可以指全连接层或卷积层 在Tensorflow中可以像下面这样组合这些残差单元实现ResNet:
HighwayNetworks 我想介绍的第二个非常深的神经网络结构是Highway Network。它以一种非常直观的方式建于ResNet上。Highway Network保留了ResNet中的短路通道,但是可以通过可学习的参数来加强它们,以确定在哪层可以跳过,哪层需要非线性连接。Highway Network中的层定义如下: (责任编辑:本港台直播) |