|
几天前,,英语的语音转录达到专业速录员水平,,了解到词错率仅 5.9% 背后的「秘密武器」——CNTK。但微软的成果是在英语水平上的,从部分读者留言中我们了解到对汉语语音识别的前沿成果不太了解,这篇文章将向大家介绍国内几家公司在汉语识别上取得的成果(文中提到的论文可点击阅读原文下载)。 10 月 19 日,微软的这条消息发布之后在业内引起了极大的关注。语音识别一直是国内外许多科技公司发展的重要技术之一,微软的此次突破是识别能力在英语水平上第一次超越人类。在消息公开之后,百度首席科学家吴恩达就发推恭贺微软在英语语音识别上的突破,同时也让我们回忆起一年前百度在汉语语音识别上的突破。
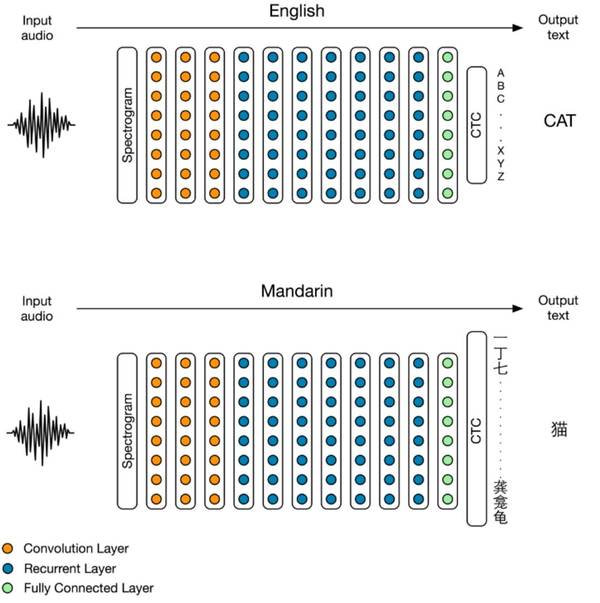
吴恩达:在 2015 年我们就超越了人类水平的汉语识别;很高兴看到微软在不到一年之后让英语也达到了这一步。 百度 Deep Speech2,汉语语音识别媲美人类 去年 12 月,百度研究院硅谷人工智能实验室(SVAIL)在 arXiv 上发表了一篇论文《Deep Speech 2: End-to-End Speech Recognition in English and Mandarin(Deep Speech 2:端到端的英语和汉语语音识别)》,介绍了百度在语音识别技术的研究成果。
论文摘要: 我们的研究表明一种端到端的深度学习(end-to-end deep learning)方法既可以被用于识别英语语音,也可以被用于识别汉语语音——这是两种差异极大的语言。因为用神经网络完全替代了人工设计组件的流程,端到端学习让我们可以处理包含噪杂环境、口音和不同语言的许多不同的语音。我们的方法的关键是 HPC(高性能计算)技术的应用,这让我们的系统的速度超过了我们之前系统的 7 倍。因为实现了这样的效率,之前需要耗时几周的实验现在几天就能完成。这让我们可以更快速地迭代以确定更先进的架构和算法。这让我们的系统在多种情况下可以在标准数据集基准上达到能与人类转录员媲美的水平。最后,通过在数据中心的 GPU 上使用一种叫做的 Batch Dispatch 的技术,我们表明我们的系统可以并不昂贵地部署在网络上,并且能在为用户提供大规模服务时实现较低的延迟。 论文中提到的 Deep Speech 系统是百度 2014 年宣布的、起初用来改进噪声环境中英语语音识别准确率的系统。在当时发布的博客文章中,百度表示在 2015 年 SVAIL 在改进 Deep Speech 在英语上的表现的同时,也正训练它来转录汉语。 当时,百度首席科学家吴恩达说:「SVAIL 已经证明我们的端到端深度学习方法可被用来识别相当不同的语言。我们方法的关键是对高性能计算技术的使用,相比于去年速度提升了 7 倍。因为这种效率,先前花费两周的实验如今几天内就能完成。这使得我们能够更快地迭代。」 语音识别技术已经发展了十多年的时间,这一领域的传统强者一直是谷歌、亚马逊、苹果和微软这些美国科技巨头——据 TechCrunch 统计,美国至少有 26 家公司在开发语音识别技术。 但是尽管谷歌这些巨头在语音识别技术上的技术积累和先发优势让后来者似乎难望其项背,但因为一些政策和市场方面的原因,这些巨头的语音识别主要偏向于英语,这给百度在汉语领域实现突出表现提供了机会。 作为中国最大的搜索引擎公司,百度收集了大量汉语(尤其是普通话)的音频数据,这给其 Deep Speech 2 技术成果提供了基本的数据优势。 不过有意思的是,百度的 Deep Speech 2 技术主要是在硅谷的人工智能实验室开发的,其研究科学家(名字可见于论文)大多对汉语并不了解或说得并不好。 但这显然并不是问题。 尽管 Deep Speech 2 在汉语上表现非常不错,但其最初实际上并不是为理解汉语训练的。百度美国的人工智能实验室负责人 Adam Coates 说:「我们在英语中开发的这个系统,但因为它是完全深度学习的,基本上是基于数据的,所以我们可以很快地用普通话替代这些数据,从而训练出一个非常强大的普通话引擎。」
|