|
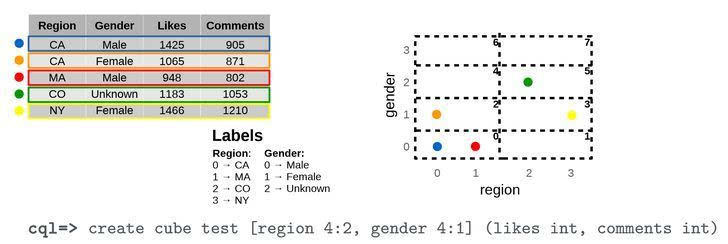
我们已经采用一种新方法而非通过预整理数据集或维护二级索引数据结构这两种方法,来解决如何跳过非必要数据以提高过滤器性能这一问题。假定系统中所有的表格都是被每一维度列进行分区排列的,我们对传统的数据库分区概念进行扩展。同时,能够预先获取每一维度列的基数,这允许我们将数据集理解为一个有更小的超立方体构成的大立方体,在一定程度上更像一个n维魔方。每一个较小的超立方体(或brick,Cubrick的一种术语表达法)代表基数函数分配的一个标识符,以一种无序且附注的形式在每一列中零散地存储数据。最后,我们假定,所有的字符串值都是经过代码编码的,内部是由单调递增的整数表示的。该假设便于我们开发一种仅在原始数据层面运行的经过优化的,精细的数据库引擎。 与其他多维数据库系统相似,Cubrick的每一列均以一种度量或一种维度进行定义,这些维度通常被用于过滤和分组,每一种度量被用于聚合函数中。图1阐释了:在一个由两个维度——区间和性别,基数为4,变化尺寸为2和1,与两种度量——喜好和评论,构成的一个数据集例子中,如何为每一模块分配数据记录。
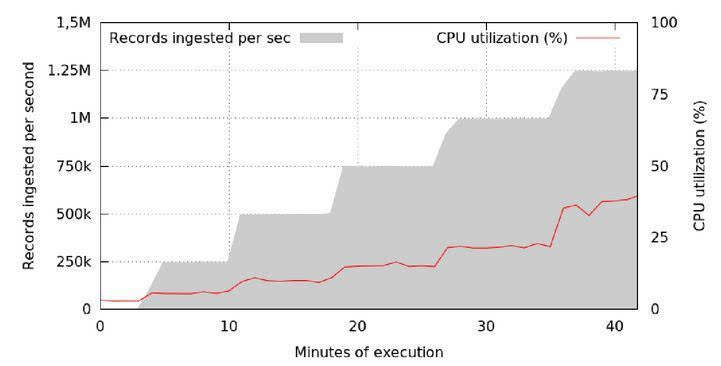
鉴于有一种连续性的时间函数将每一条记录映射到与之相匹配的目标模块中,直播,而且每一模块中的数据都是无序排列的,这种简单却有效的数据管理方法考虑到非常有效的记录插入。此外,如果在搜索空间内没有插入记录,在查询时间段内,每一模块都能够轻松地与查询过滤器相匹配,并得到梳理。 实验结果 为了评估Cubrick获取记录的速率与获取记录通道所占用的CPU,图8所示为:与CPU占用量相比,每个单一结点簇每秒获取的记录数量。本实验得出以下结论:即使每秒获取的记录数量达到100万,每个单一结点簇所占用的CPU依然处于低水平(20%以下)。
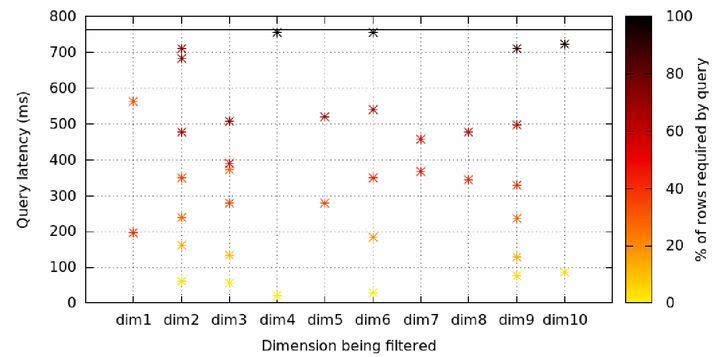
注:当获取不同容量大小的记录时,每个单一结点簇的CPU占用情况 图7所示为在一个72个结点簇处运行的10TB数据集存在的多种潜在查询,旨在评估我们的索引策略是否有效。X轴代表应用过滤器的列,颜色标尺为这种过滤器的局限性,或该数据集与过滤器之间的匹配百分比。实验结果显示,Y轴上的颜色与位置存在明显关联性,与X轴上的位置不相关。换句话来讲,不论处于哪一列,当运用过滤器时,查询速率将得到很大程度的提升。
注:在一个72个结点簇处运行的10TB数据集经不同维度过滤后存在的多种潜在查询 请参考我们在2016年国际顶级数据库会议上发表的论文,获得完整的实验方法与结果。 瞻望未来 在过去几年内,Facebbook曾在多个实时(批量)交互式分析应用实例中采用Cubrick,Cubrick正在迅速成长为一个更为成熟的全功能数据管理系统。关于如何更加有效地处理具有不同数据分布特征的数据集与使这种立方体图式更具动态化,我们还要进行大量的研究求证。我们相信,Cubrick的研发是我们朝向这一目标迈进的第一步,不过,目前该研究领域还存在几个尚未探索且有趣的主题等待我们开展研究。 (责任编辑:本港台直播) |